|
Achtung: Dieser Text ist mit Unicode / UTF8 kodiert.
Um die in ihm erscheinenden Sonderzeichen auf
Bildschirm und Drucker sichtbar zu machen, muß ein Font installiert sein, der
Unicode abdeckt
wie z.B. der TITUS-Font
Titus Bitstream Unicode. |
Attention: This text is encoded using Unicode / UTF8.
The special characters as contained in it
can only be displayed and printed by installing
a font that covers Unicode
such as the TITUS font
Titus Bitstream Unicode. |
III. უდიური ენის მონაცემთა ელექტრონული ბაზის
მოდელირებისათვის
უდიური ენის მონაცემთა ელექტრონული ბაზა წარმოადგენს უდიური
ენის მორფო-ლექსიკოლოგიურ ელექტრონულ ლექსიკონს და აგებულია
მონაცემთა ბაზის მოდელირების ძირითადი პრინციპების
გათვალისწინებით. ბაზა წარმოადგენს ტაბელთა სიმრავლეს, რომელიც,
თავის მხრივ ჩანაწერთა სიმრავლისაგან შედგება. ბაზის სტრუქტურა
სქემატურად ასე იქნება წარმოდგენილი:

თითოეულ ტაბელში განსაზღვრულია ჩანაწერის გარემო, რომელიც
ატრიბუტებისაგან შედგება, ანუ მოცემულია სალექსიკონო ერთეულის
გრამატიკული და მორფოლოგიური დახასიათება, რომელიც ჩანაწერის
ველებშია განთავსებული. ფორმაცვალებადი სალექსიკონო ერთეულისათვის
ერთმანეთისაგან განვასხვავებთ ძირითად (A), მორფოლოგიურ (B) და
ლექსიკოლოგიურ (C) ველებს. თითოეული ჩანაწერის პირველად გასაღებს
წარმოადგენს ბაზაში მისი საიდენტიფიკაციო ნომერი, ძირითად და
მორფოლოგიურ ველებში დამატებით მოცემულია ჩანაწერის მეორადი და
მესამედი გასაღები - სალექსიკონო ერთეულის სტრუქტურული და
მორფოლოგიური ინდექსი (ფუძის სტრუქტურული და მორფოლოგიური
მახასიათებელი).
ჩანაწერის გასაღების მეშვეობით ხორციელდება მონაცემთა
ვირტუალური წარმოდგენიდან მის ფიზიკურ წარმოდგენამდე მიღწევა,
კერძოდ, პირველადი გასაღების მეშვეობით ხორციელდება ჩანაწერის
ცალსახა იდენტიფიკაცია, ხოლო მეორადი და მესამედი გასაღების
მეშვეობით კი ბაზის ჩანაწერთა სიმრავლიდან ერთგვაროვან ერთეულთა
გამორჩევა. მონაცემთა ბაზა რეალიზებულია რელაციური მოდელის
მოთხოვნათა შესაბამისად (ჯ. ულმანი) და აქტუალიზებულია მონაცემთა
ბაზების მართვის სისტემის FoxPro for Windows 2.6 და Visual FoxPro 3.0
პროგრამულ გარემოში. ქვემოთ განვიხილავთ მონაცემთა ბაზაში
ლექსემათა ფიზიკური წარმოდგენის მოდელს.
არსებითი სახელი მონაცემთა ბაზაში წარმოდგენილია სამი ველით:
A, B და C. ძირითადი (A) ველი შედგება ქვეველებისაგან: A1-ში
მოცემულია არსებითი სახელი სახელობით ბრუნვაში; A2-ში - მისი
ქართული თარგმანი (პირველადი გასაღების შესაძლო ვარიანტი); A3 და
A4 -ში - ფუძის ინდექსი (ფუძის შინაარსობლივი და სტრუქტურული
მახასიათებელი);
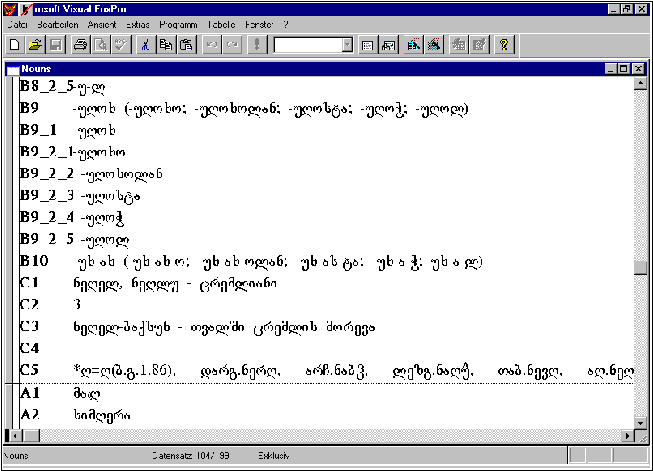
მორფოლოგიურ (B) ველში ასახულია ჩანაწერის ატრიბუტები -
არსებით სახელთა მორფოლოგიური კატეგორიები: რიცხვის კატეგორია
(მითითებულია მრავლობითი რიცხვის მორფემა) და ბრუნვის კატეგორია;
იმ შემთხვევისათვის, როდესაც ბრუნვის ნიშნის დართვა იწვევს
ფონეტიკურ ცვლილებებს, გათვალისწინებულია ქვეველი
რეკონსტრუქციებისათვის.
ლექსიკოლოგიური ველიც ქვეველებად არის დაყოფილი: C1 ქვეველში
მოცემულია დერივაციული ფორმები, ამდენად, ჩანს სალექსიკონო
ერთეულის დერივაციის უნარი. მაგ. ქულ - ხელი, ქულნუთ - უხელო; C2
ქვეველში მოცემულია ინდექსი, რომლის მეშვეობითაც შეგვიძლია
მოვახდინოთ იდეოგრაფიულ ჯგუფთა გადარჩევა. C3 ქვეველში მოცემულია
მყარი ფრაზეოლოგიური გამოთქმები, ისეთი სინტაგმები, რომლებშიც
ყველაზე ხშირად მონაწილეობს სალექსიკონო ერთეული და
შინაარსობლივად მასთან ახლოს მდგომი სიტყვები. ამ ქვეველში
მოცემულია ლექსემის სემანტიკური აქტანტები, როგორც პარადიგმატული,
ისე სინტაგმატური. მაგ. ტულ - ყურძენი ლექსემის C3 ქვეველში
მოცემულია პარადიგმატული აქტანტებია: ტულლა იმაჯი - რთველი, ღომა
- მტევანი, გილა - მარცვალი, ჭაპ - ვაზი, ჭაპლუღ - ვენახი, φი -
ღვინო; ქულ - ხელი ლექსემის C3 ქვეველში მოცემულია სინტაგმატური
აქტანტებია: ქინ კაშა - ხელის თითი, ქულქეხ ბიყსუნ - ხელის
ჩამორთმევა; C4 ქვეველში მოცემულია სინონიმები. მაგ. ლექსემა
ჭაპლუღ - ვენახის C4 ქვეველში წარმოდგენილია მისი სინონიმი გა.
C5 ქვეველში მოცემულია ლექსემის ეტიმოლოგია: ა) მითითებულია,
საერთო-კავკასიური ძირია, ინდოევროპული თუ სხვა; ბ) მოცემულია
შესაბამისი ფორმები სხვა კავკასიურ ენებში; მაგ. ხურძურში,
დარგუულში, ლაკურში, ლეზგიურში და ა. შ.; გ) დასახელებულია
ბიბლიოგრაფია (ავტორი, ნაშრომი, გვერდი);
ზედსართავი სახელის ლექსიკოლოგიური ველის ქვეველები
სტრუქტურირებულია არსებითი სახელის ლექსიკოლოგიური ქვეველების
მსგავსად, თუმცა მისგან განსხვავებით, გააჩნია ანტონიმური
ქვეველი, სამაგიეროდ, არ გააჩნია იდეოგრაფიული ქვეველი.
ანტონიმურ ქვეველში მოცემულია ზედსართავ სახელთა ანტონიმები.
მაგ. შელ - ფის (კარგი - ცუდი); ბუჲ - ამწი (სავსე - ცარიელი);
მაწი - მა'ჲნ (თეთრი - შავი) და ა. შ.
რიცხვითი სახელების მონაცემთა ბაზა უდიური ენის ელექტრონულ
ლექსიკონში აერთიანებს რაოდენობით, რიგობით და დაშლით-დანაწევრებით სახელებს. ეს სახელები, ზედსართავი სახელების
მსგავსად, ორგვარად არის შესული მონაცემთა ბაზაში: როგორც
ატრიბუტული სახელი და როგორც გასუბსტანტივებული სახელი. პირველ
შემთხვევაში იგი, როგორც არაფლექსიური სიტყვაფორმა, მორფოლოგიური
ველის გარეშე არის წარმოდგენილი, მეორე შემთხვევაში კი ისე,
როგორც ფლექსიური (მაგ. სუბსტანტივები) სიტყვაფორმები.
რიცხვით სახელთა ლექსიკოლოგიური ველი შედგება C1, C2, C3 და C4
ქვეველებისაგან და შესაბამისად გვიჩვენებს რიცხვით სახელთა
დერივაციის უნარს, სინტაგმებსა და მყარ ფრაზეოლოგიურ გამოთქმებში
მათ მონაწილეობას; წარმოდგენილია სინონიმები და
ეტიმოლოგია.
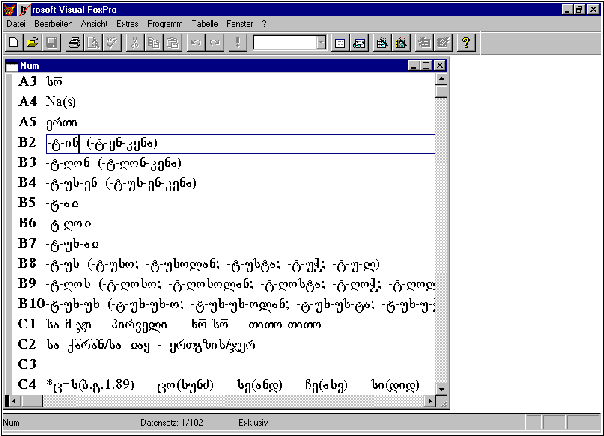
მონაცემთა ბაზა ვართაშნული დიალექტის მასალაზეა აგებული,
თუმცა ხშირ შემთხვევაში, უმეტესად კი სინონიმურ ქვეველში, ნიჯური
დიალექტის მასალაცაა მოცემული. ეს ქვეველი თურქულ-აზერბაიჯანულიდან შემოსულ ლექსიკურ მასალასაც ასახავს.
მაგ. ხიბყო-ვიწ - სამოცდაათი (60 - 10) ნიჯურში გააჩნია
სინონიმი ვუ'ღ-ვიწ (შვიდი -ათი). გარდა ამისა გვხვდება აგრეთვე
აზერბაიჯანულიდან შემოსული ჲეთმიშ. ორივე ეს ლექსემა შეტანილია
C3 ქვეველში, როგორც სინონიმი.
ნაცვალსახელთაგან უდიური ენის ელექტრონული ლექსიკონი
აერთიანებს პირის, ჩვენებით, კუთვნილებით, კითხვით, უკუქცევით და
განუსაზღვრელ ნაცვალსახელებს.
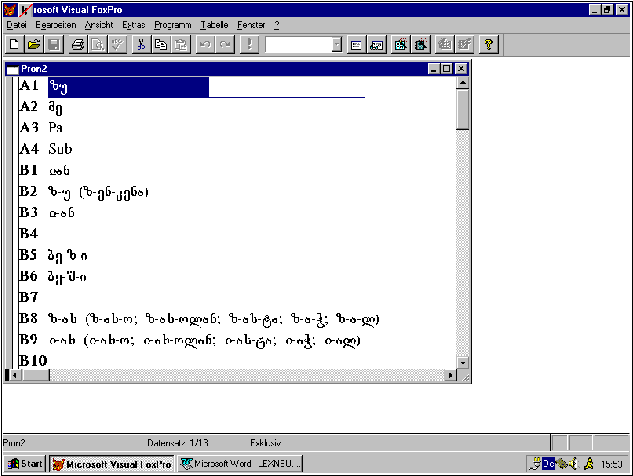
ნაცვალსახელთა მორფოლოგიური ველი შეიცავს მათ მორფოლოგიურ
დახასიათებას, წარმოდგენილია ბრუნვისა და რიცხვის კატეგორიები,
ლექსიკოლოგიური ველი კი შეიცავს მხოლოდ ეტიმოლოგიურ ქვეველს.
ზმნა უდიური ენის ელექტრონულ ლექსიკონში სამი ველით არის
წარმოდგენილი: A, B და C. ძირითადი (A) ველი ქვეველებად არის
დაყოფილი: A1-ში მოცემულია სალექსიკონო ერთეული - ინფინიტივ-მასდარი; A2-ში თარგმანი; A3-ში - ზმნის სტრუქტურული
მახასიათებელი; იმის გამო, რომ ზმნის მოდელირებისას ერთ-ერთ
არსებით ატრიბუტად მიჩნეული იქნა ზმნის სინტაქსური კონსტრუქცია,
ეს უკანასკნელი კი არსებითად პირის პირის ნიშანთა სერიებთან არის
დაკავშირებული (განსაზღვრავს პირის ნიშნის სერიას), B ველში
შევიტანეთ ზმნის არსებით პარამეტრთა ამსახველი B1 და B2
ქვეველები: B1-ში მოცემულია ზმნის სინტაქსური კონსტრუქციის
იდენტიფიკატორი; B2-ში მოცემულია პირის ნიშნის სერიათა
იდენტიფიკატორი; B3-ში მოცემულია ზმნის დრო-კილოთა კონსტანტები
(C1, C2 და C3); B ველის დასახელებული ქვეველები ზმნის მორფო-სინტაქსურ დახასიათებას შეიცავს, რის გამოც იგი შეიძლება
დახასიათდეს, როგორც მორფო-სინტაქსური ველი.
ლექსიკოლოგიური ველი (C) შეიცავს რამდენიმე ქვეველს: C1 -
სინონიმური ქვეველი; C2 - ეტიმოლოგიური ქვეველი;
გარდა ზემოჩამოთვლილი ფორმაცვალებადი სიტყვებისა, უდიური
ენის მონაცემთა ბაზა შეიცავს აგრეთვე ფორმაუცვლელ სიტყვათა ბაზას,
რომლის სტრუქტურაც მხოლოდ ორი, A და C ველებით არის
წარმოდგენილი.
ძირითადი (A) ველის ქვეველებში, ისევე, როგორც
ფორმაცვალებადი ლექსემების შემთხვევაში, მოცემულია ფორმაუცვლელი
ლექსემა (A1 ქვეველი), მისი თარგმანი (A2 ქვეველი) და ინდექსი,
ფორმაუცვლელ სიტყვათა რომელ ჯგუფს მიეკუთვნება იგი (A3).
ლექსიკოლოგიური (C) ველი წარმოდგენილია სინონიმური (C1) და
ეტიმოლოგიური (C2) ქვეველებით.
უდიური ენის მონაცემთა ჩვენ მიერ წარმოდგენილი ბაზა ქართული
სატრანსკრიფციო სისტემით არის შექმნილი. საჭიროების შემთხვევაში
ლათინურ ტრანსკრიფციაზე მისი გადაყვანა სირთულეს არ წარმოადგენს.
ბაზასთან ოპერირებისათვის (ძირითადად სელექციისათვის)
გამოყენებულია ბრძანებათა ბლოკი: set filter to “X” $ F; set filter to alltrim
(F) = “X”; set filter to empty (F); set filter to not empty (F); კომპლექსური
დამუშავებისათვის კი გათვალისწინებულია მცირე პროგრამული
საშუალებები.
ბაზის მოცემული სტრუქტურა, კერძოდ ბაზაში მონაცემთა ფიზიკური
წარმოდგენის მოდელი, საშუალებას იძლევა მრავალი თვალსაზრისით
დავამუშაოთ საკვლევი ენის მასალა; გამოვიყენოთ იგი როგორც
ლექსიკოგრაფიული (მაგ. სხვადასხვა ტიპის ლექსიკონების -
ორენოვანი, ინვერსიული, სინონიმური, იდეოგრაფიული, ეტიმოლოგიური
და ა. შ. შესადგენად), ისე სხვა ლინგვისტური მიზნებისათვის.
მსგავსი ბაზების არსებობა სხვა იბერიულ-კავკასიური
ენებისათვის დააჩქარებს კავკასიურ ენათა კომპლექსურ კვლევას და
მყარ საფუძველს შექმნის იბერიულ-კავკასიურ ენათა უახლესი
ტექნოლოგიური საშუალებებით კვლევის განხორციელებისათვის.
Copyright Manana Tandashvili
Tbilisi 1999. No parts of this document may be republished in any form
without prior permission by the copyright holder.