
Unicode® as a worldwide character encoding provides the foundation for worldwide communica-tion between peoples, cultures and civilizations. Within the Worldwide Web, Unicode will soon ensure a nearly unlimited data flow across national boundaries, across continents and cultural regions, without these data being equalized in script and format so as not to exceed the character processing capabilities of computers connected to the net. Original script data will be transported instead, which can be marked as respresenting a specific language.
Every civilization will then be able to expose itself on the WWW by means of its own communication code which includes writing system, language and many other audio-visual elements. The world will meet on the net, in all its diversity, multiscript and multilingual documents of all kind (texts, sound files, videos) will circulate so as to internationalize business and private communication, education, planning of touristic activities, entertainment.
This world. however, does not exist from each day's dawn on. Our world has a memory. In this respect, the world may be compared with an organism registering all events encoutered during its existence. Man is a part of this huge organism. With the help of his will, he can of course cherish the illusion to break with his ties to the world organism, but in reality man in unable to do so. His reasoning depends from what has happened before in his own life, but also from what he has been told to have happened in the past long before his lifetime. The people who are teaching him are those who live together with him in the society which as a whole considers its behaviour as an expression of its identity. Like this, society in its turn is an organism located in between the individual and the entirety of mankind. When we regard society in a historical perspective, observing the continuity of cultural features in the course of time, then we are talking about a civilization.
Civilization and language community are, of course, not identical. One civilization can encompass several language communities. On the other hand, one language community may also spread over civilization boundaries, although such a constellation is rather rare.
1. What is the memory of the world?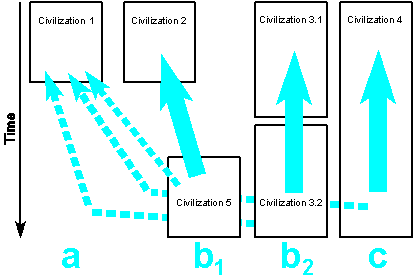
What does this memory consist of? The world's memory can be defined as the total of the memories of its civilizations, ancient and modern. Human civilization grew up at various points on the earth and developed various ways to fix human feeling and thought. The most important development is writing which began at about 3000 B.C. From this moment onwards human thought can be traced back and so a civilization is able to follow up its identity in the past provided that written records are preserved.
When talking about the memory of the world we should like to distinguish three categories:
(a) Memory extinguished at a certain moment when the civilization disappeared, and now, after a period of hundreds or thousands of years, revealed and retraced by other people discovering and studying the written documents. The ancient civilizations of Mesopotamia are an example of this category, their cuneiform documents being examined by scholars from all over the world because of the importance of these civilizations for the history of mankind.
(b) Memory extinguished during a certain period and discovered again at modern times, just as in case (a), but claimed by modern civilizations which recognize themselves as continuants of the ancient culture even if this claim is rather emotional and cannot be proven. The Egyptian people e.g. is right in considering the ancient hieroglyphs as an early expression of their own culture, although they adopted an islamic civilization and use the arabic script and language since then (we may label this case b2). In the case of the script of the Indus valley, however, the situation is more complex, for up to this day we do not dispose of an acceptable decipherment. Nevertheless, a number of ethnic groups adhering to certain deciphering proposals pretend the characters to convey a historic stage of their own language (b1).
(c) Memory that never extinguished but has been maintained up to our times, considered as foundation of the civilization or part of the civilization which claims it. The Greeks e.g. can retrace their civilization through an unbroken written tradition up to the Bronze age records of the Mycenaeen period. The Indo-Aryan peoples of South Asia, although nowadays diversified in many nations, possess a great textual monument from about 1200 B.C., the Vedic Samhits, which witness to the invasion and the establishment of Indo-Aryan ethnic groups in the subcontinent.
There is, however, one important point to be noted here: Besides the memory preserved by writing,
there exists a memory that is handed down exclusively by an oral tradition, even over a period of
many hundred years. It is one of the challenges mankind faces in our time, to save these oral
traditions before they disappear. Consequently, recording, describing and analyzing an oral tradition
belongs to the scope of a paper dealing with the memory of the world, but I would like to postpone
it to a later occasion and to focus the attention on the written documents.
2. What is the role of the civilizations' memory in everyday's worldwide communication?
The written memory of type (a), being the findings of archaeology, serves a double purpose: First the contents of these documents make us conscious of the condition of human life on earth, of what a civilization needs to prosper, to degenerate and to vanish in the course of history. This is the didactic aspect of the history of dead civilizations: Man is looking into the past like into a mirror, discovering patterns of his own behaviour. Second there is the interest in extinct communication systems as documented by the written records. The analysis of these records does not only pertain to the writing system and the scripts used but also to communicative elements other than writing (symbols, paintings etc.).
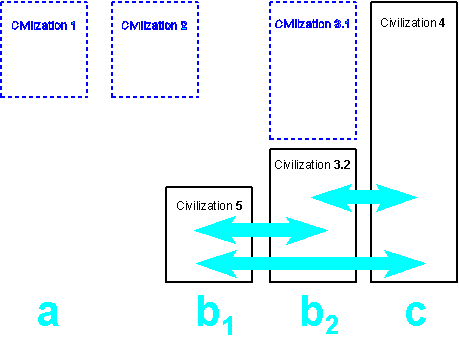
The memory of category (b), however, grants the cultural identity of the civilization which preserves it, providing the feeling of cultural uniqueness. In the course of its development a given civilization borrows plenty of its aesthetic expressions not only from neighbouring civilizations but also from its own history in order to maintain and interpret anew its reason for being. A distinct lifestyle in a certain culture cannot be defined without regarding what has been thought and feeled in the past. Similarly, religious communities that may be independent of national boundaries, refer to their key texts that belong to the memory of the civilization in the midst of which the fundamental ideas were first thought, formulated in language and written down by means of the writing system in use.
Any communication going beyond the essential needs of everyday's life refers to cultural themes
that involve the memory of the civilization the communication starts from. Therefore a
communicative act that happens between members of different civilizations always conveys
elements of the memories of these civilizations. This is what American and European commercial
companies recognized when developing marketing strategies for countries outside western
civilization. In order to sell a product e.g. in Thailand, it is very important the publicity appeals to
ideas and feelings intrinsic to Thai civilization. Naturally, these ideas can be formulated by means
of the current language, but this is impossible without consulting from time to time the original
documents. Consequently, as long as civilizations adhere to their identity, their written memory
must remain as easily accessible as the informations of everyday's life.
3. Who does administer the memory of the world?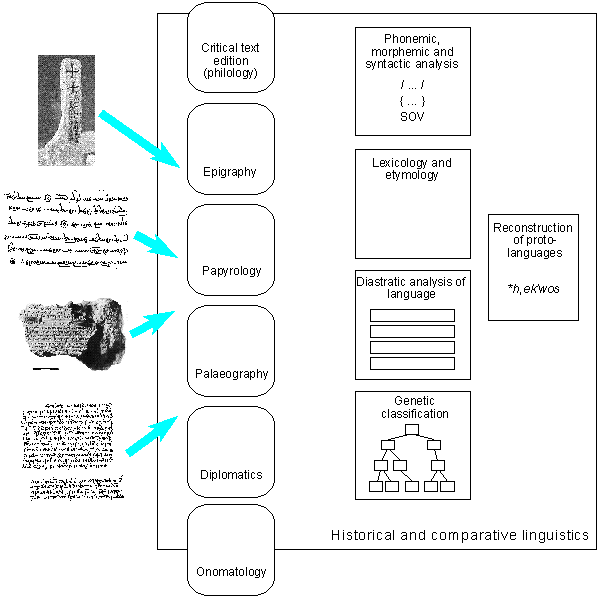 Administering the memory of a civilization requires competence. Just as the maintenance and the
restauration of ancient architectural monuments has to be done by specialists, investigation, storage
and analysis of the written memory of the world are the tasks of scientists who received a special
education. This slide shows how the relevant academic disciplines are arranged in a functional
framework. Historical and comparative linguistics is the all-encompassing discipline, depending on
a number of highly specialized branches that function like filters the primary material has to pass
through before the linguistic analysis proper can be started on. The images on the left symbolize
different kinds of ancient text documents, i.e. texts preserved on various physical matter: stone,
clay, wood, papyrus, paper, etc. There are scientific disciplines working on documents preserved on
certain materials (epigraphy, papyrology) or on hand-written documents, i.e. manuscripts
(diplomatics), others treat the classification of scripts and letter shapes (palaeography), and the
philological branches of literary studies in every language community are concerned with the
establishment of text editions exhibiting the variant readings of several copies of the same text in
a so-called critical apparatus. Of course the boundaries between these fields of academic work are
not absolute. Critical text edition, for example, is also practised by epigraphists in case an
inscription happens to be preserved on different stones.
Administering the memory of a civilization requires competence. Just as the maintenance and the
restauration of ancient architectural monuments has to be done by specialists, investigation, storage
and analysis of the written memory of the world are the tasks of scientists who received a special
education. This slide shows how the relevant academic disciplines are arranged in a functional
framework. Historical and comparative linguistics is the all-encompassing discipline, depending on
a number of highly specialized branches that function like filters the primary material has to pass
through before the linguistic analysis proper can be started on. The images on the left symbolize
different kinds of ancient text documents, i.e. texts preserved on various physical matter: stone,
clay, wood, papyrus, paper, etc. There are scientific disciplines working on documents preserved on
certain materials (epigraphy, papyrology) or on hand-written documents, i.e. manuscripts
(diplomatics), others treat the classification of scripts and letter shapes (palaeography), and the
philological branches of literary studies in every language community are concerned with the
establishment of text editions exhibiting the variant readings of several copies of the same text in
a so-called critical apparatus. Of course the boundaries between these fields of academic work are
not absolute. Critical text edition, for example, is also practised by epigraphists in case an
inscription happens to be preserved on different stones.
The most intensive mutual exchange, however, takes place between these special textual sciences and historical and comparative linguistics. Language analysis is practised within the boundary of the philological sciences, epigraphy and diplomatics, whereas historical and comparative linguistics only provides the methods to be applied. Furthermore, the treatment of the most ancient texts is impossible without a comparative approach. When analyzing ancient language material we have to start from both the modern representatives, i.e. the living languages genetically related to the ancient language of the document, and the evidence yielded by language comparison and reconstruction. In case no modern language appears to continue the language of the document, the approach "from behind" applying comparative evidence is even the only possible one.
The treatment of language data within historical and comparative linguistics is based upon the methods and findings of the other linguistic disciplines (phonetics, general linguistics, computational linguistics), its aims is, however, to explain the development and change of language in the course of time. Therefore, phonemic, morphemic and syntactic analysis is always performed in a diachronic perspective. Similarly, historical and comparative linguistics supplements lexicology with etymology, the "history of words and their meaning". As a result, different historical layers of a language can be defined (diastratic analysis) and different languages in their turn can be classified according to their mutual genetic relationship. From the comparative evidence, proto-languages are inferred: the reconstructed data of a proto-language help to determine the structure of an ancient language poorly documented by a few texts only.
Corresponding to its nature, historical and comparative linguistics is an international discipline. Of course the memory of a still living civilization is first collected and worked on by its own members who acquired the scientific education necessary. But as civilizations communicate, also the interest in their traditions becomes part of the mutual exchange, all the more when the cooperation with foreign specialists establishes relations and yields new insights in the character of each civilization. The remnants of ancient civilizations should be considered as a possession of mankind.
It is exactly with these ideas in mind that UNESCO developed the program "Memory of the world"
(cf. http://www.nla.gov.au/3/npo/intco/memory.html) in order to save the surviving documents of
the world's civilizations. I just described the scientific apparatus that has to assist UNESCO in
executing the programme.
4. How are the ancient documents handled by the textual sciences?
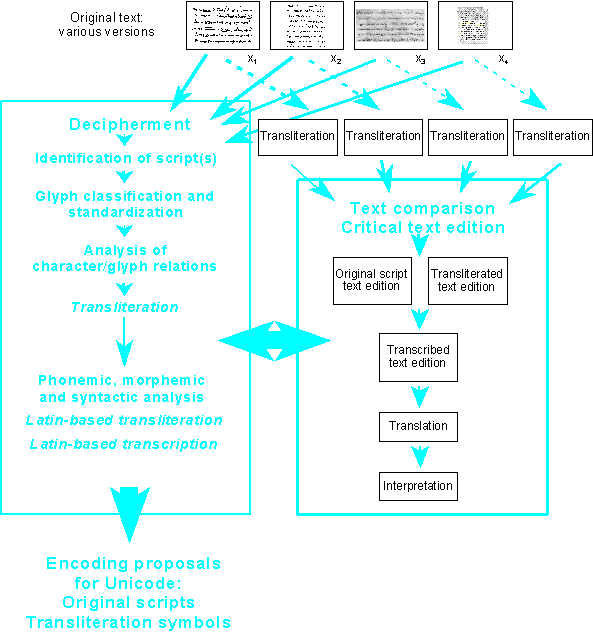
In order to understand the complexity of the handling of ancient text documents we should pay attention to the different steps undergone while preparing a text edition, which in its turn marks the starting point for the interpretation of its contents.
Let us take for example an ancient text preserved in four manuscripts, and let us suppose that we know nothing about the script and the language of the text. We have to distinguish two working areas, one entitled 'Decipherment', the other 'Text comparison / Critical text edition', exchanging continuously the results achieved. Decipherment is used as a label for the linguistic treatment of the data. The first step consists in identifying the script or scripts the documents exhibit. A script has to be described by determining the distinctive forms of its units and deriving standard forms of each unit. In doing so the functional units of the script can be defined, i.e. a Unicode conformant character/glyph analysis can be performed already at this stage. For the scientific notation, we may design a transliteration for the script, using symbols like numbers but not letters of any other script since at this level of analysis we are not to presume any phonic interpretation. Thus we can transliterate the versions of the original text without having an idea of the language it transports.
The decipherment proceeds by testing different phonetic values with the script units. External factors like a translation of the text into a known language or archaeological data facilitate the task. Once a reading has been established that can be proven by internal as well as external, i.e. comparative, evidence, linguistic analysis determines the phonemic system, morphemic units and the syntactic structures. After that we are allowed to substitute the transliteration symbols with latin-based characters and so to mime the graphical units the original script uses, but now with regard to their phonetic value. Transcription, however, renders the graphemic and phonemic interpretation of the original script and is totally independant of graphical shapes of the original script. As far as the treatment of the script is concerned, the character/glyph evaluation will not be altered by the linguistic analysis of the language material written down, but only the functional description of characters and glyphs is specified in greater detail. At the end of the deciphering process linguists are able to propose a script encoding for Unicode as well as additional modifier letters needed for a latin-based transliteration.
In the domain of 'Text comparison / Critical text edition' our ancient text documents can be treated according to the level of analysis performed in the course of the decipherment process. Text comparison yields an edition of the text which establishes one reading text and lists the variant readings in a critical apparatus after having evaluated their quality. Theoretically a text edition may offer a transliteration immediately after the script analysis, i.e. without regard to the linguistic units. The glyph standardization allows for a rendering of the text in original script. The edition will of course be more useful if the linguistic information is available and a transcription can be made. Only such an edition can serve as a reliable text for further investigation and treatment, i.e. translation and interpretation.
Parts of the working process may be taken on by special scientific disciplines presented on slide 3. Historical and comparative linguistics, however, provides a sort of common ground for the conservation of ancient text documents. At any rate, historical and comparative linguistics assumes the task in case no particular branch of research exists that could undertake the analysis.
5. How can a WWW server expose the written memory of the world?
The TITUS server - a pioneering project.
 http://titus.uni-frankfurt.de/
http://titus.uni-frankfurt.de/
TITUS is an acronym for 'Thesaurus Indogermanischer Text- und Sprachmaterialien', in English: 'Thesaurus of Indo-European Text and Language Materials'. Indo-European linguistics is the most important branch of historical and comparative linguistics since it analyzes the history of the best documented language family of the world. The civilizations using Indo-European languages dispose of particularly ancient and rich textual traditions attesting their development from about 1700 B.C. onwards.
The idea of the TITUS project was born in 1987 in Leiden (Netherlands) when at the Conference on Indo-European linguistics a small group of linguists talked about the cooperation possibilities in order to avoid multiplying the same effort when entering ancient texts into the computer. An announcement of the database project in the review 'Die Sprache' vol. 32/2, 1987, followed this discussion. The main initiator and coordinator of the project is Jost Gippert, since 1994 professor for comparative linguistics in Frankfurt/M., Germany; the Institute of Ancient Near Eastern Studies at the Charles University, Prague, and the Linguistic Department of the University of Copenhagen are important partners. Since 1994 the project has its Web site in Frankfurt, and in October of the same year it was given its final name with the convenient acronym and joined the 'Gesellschaft für linguistische Datenverarbeitung / Linguistic Data Processing Association', as working group 'Historical and Comparative Linguistics'.
After nearly 10 years the size of the TITUS database has been steadily increasing so that we can be quite sure in 2000 to present a CD-ROM containing all texts relevant to Indo-European linguistics. At the time being about 2,5 GB of text materials a stored in Frankfurt. The project actually has 85 registered collaborators from all over the world.
The most severe technical obstacle the TITUS project met with during all the years of its existence was and still is the absence of a character encoding standard exceeding the limits of 8-bit processing. When transfering linguistic data through the internet the restrictions are even greater given that currently the only worldwide standard is the 7-bit ASCII. In the 8-bit area, font technology only hides the encoding problem when in foreign language (i.e. non-English) fonts outlines are put on code positions the values of which vary according to the operating system and/or to the local standard encoding. Nevertheless, it was of course feasible to store and retrieve the data as long as a fully reversible encoding was applied with the help of sequences of ASCII characters that on every platform can be converted to a WYSIWYG rendering by a special font. We hope that in a near future Unicode and further planes of ISO 10646 will offer a final solution for encoding historical language materials.
Another difficulty is the copyright question. When the TITUS project is going online, it has to respect the copyrights of editors and publication houses. So the text database as a whole cannot be opened for everyone interested. In case the editor and contributor allows for free distribution and use of his work, the text can be downloaded. It does not need to be commented that any further use of the material must follow the conventions of scientific publication, i.e. the source has to be specified at every occasion.
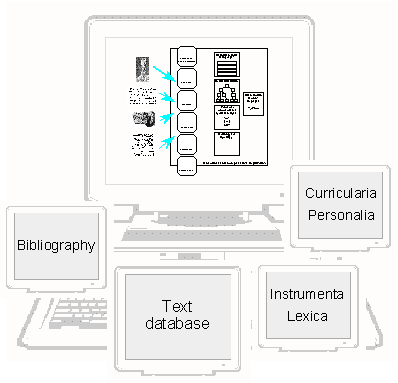
The heart of the TITUS server is the text database, but TITUS meanwhile has become a data pool.
Many categories of information about Indo-European comparative linguistics, the institutions of the
discipline and the researchers working there, about scientific publications, are collected and
exposed on the server. Storing and retrieving ancient texts as well as bibliographic data involve
script encoding: Therefore, these sections of TITUS are presented in more detail on the following
slides.
 6. Handling example epigraphic documents:
Ogam inscriptions.
6. Handling example epigraphic documents:
Ogam inscriptions.
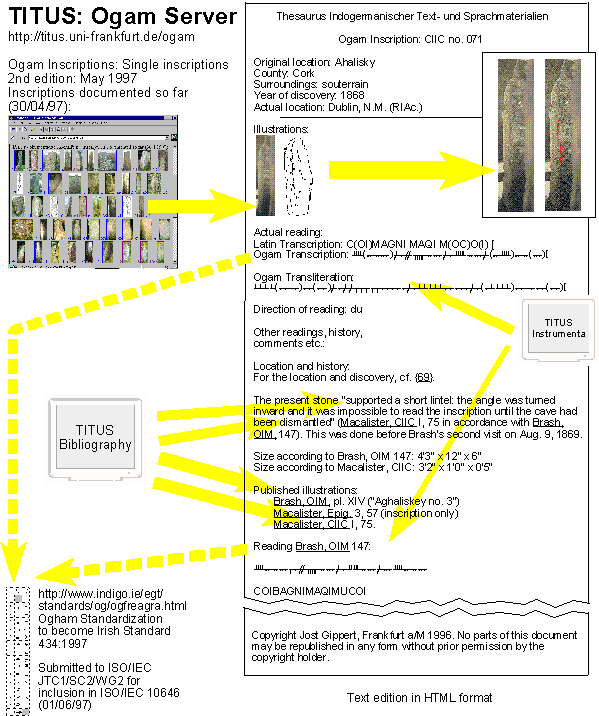
If you want to see how a WWW edition of epigraphic documents will look like in the future, you may visit the Ogam server being a section of TITUS, designed and maintained by Jost Gippert. You start browsing the inscription written in Ogam, the ancient script of the Celts used during the early Middle Ages, from a gallery of thumbnail images showing all the stones included so far. By a mouse click you choose one of them and switch to the page where the monument is dealt with: This is a scientific HTML text edition. First the location data are given, then thumbnail images again from which the user can move to colored high resolution photographs. In this way, the monument and especially the inscribed area is documented in best quality. Additionally there are modified photographs with marks highlighting the engravings as well as drawings taken over from earlier publications. Consequently, depending on the quality of the monitor, the user has the best available pictures of the monument at his disposal and is able to verify the reading of the inscription directly on the photograph.
The treatment of the inscription then follows the steps discussed above in slide 4. The original script rendering is given in two versions, the first being a notation by standard glyphs, the second depicting the arrangement of the script units on the stone. The first rendering is called transcription because it introduces a script normalization and like this an interpretation of the actual engravings, whereas the second Ogam line is a transliteration by definition. The Ogam script has been prepared for encoding in Unicode by NSAI/AGITS/WG6, the Working Group for Irish standardization in the field of Character Set Technology and Cultural Elements. The discussion on glyph standardization, character definition and standard character names has been carried on via the WWW so that the international scholarly community could participate in the preparation process. We hope that ISO/IEC JTC1/SC2/WG2 will support the inclusion of Ogam into ISO 10646. Currently the Ogam notations on the Web pages can only be viewed if the TITUS Ogam font has been downloaded from the server and installed on the computer the browser is running on. This TITUS Ogam font contains all the outlines required for a correct display of the entire page, i.e. the Western Latin Charater Set as well as symbols used for editorial purposes, and the Ogam characters. In case Ogam will be included in Unicode, we still will have need of a special font but then every Unicode conforming typeware containing Ogam outlines can be applied since the encoding is standardized.
The next section of the WWW edition page displays the scientific work done on the inscription up to now. Reports, readings and archaeological and linguistic comments made by scholars from the beginning of Ogam research are presented in Hypertext format, i.e. the informations are linked to other sections of the server, especially the electronic bibliography and the other text edition pages within the Ogam server. Of course each element on these pages is subject to copyright restrictions as indicated at the relevant objects and at the bottom of each page.
This Ogam project is still in progress, the missing inscriptions will soon be added. We hope that the
scholarly community will promote the Frankfurt Ogam server to one of the most important Ogam
Web sites of the world.
7. Handling example manuscript document:
Avestan hymn to Haoma (the intoxicative drink).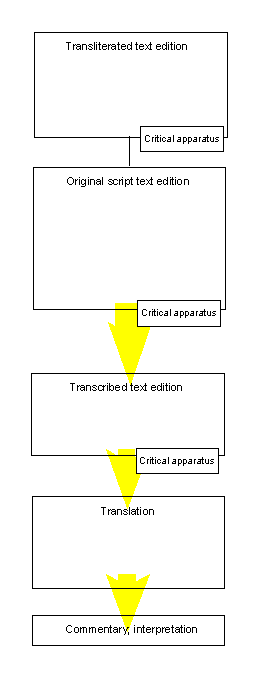














The Avesta corpus, the sacred texts of the Zoroastrian religion and thus the key texts of pre-islamic Persia, are preserved by a manuscript tradition which in course of time became considerably diversified and intricate because important pieces got lost. Therefore, editing the Avestan texts means first to establish a stemma, i.e. a 'genealogical' tree, of the available manuscripts.
Zoroastrian priests developed a special phonetic script in order to fix the Avestan language, an earlier and a later stage of which is transmitted in the text corpus. This script creation took place at a certain time during the Sasanian empire (224-651 A.D.) on the basis of the so-called Pahlavi script, i.e. the Middle Persian Book Script. Many of the Avestan letter forms are particular to this script which requires a separate encoding in Unicode (cf. IUC 10, Presentation C11 "Unicode, Ancient Languages and the WWW"). Avestan manuscripts normally contain a Middle Persian translation (cf. the characters on grey background in the manuscript J2) written in Pahlavi, some also a Sanskrit translation. Additionally, a commentary in Middle Persian and in Sanskrit can be interspersed.
This slide illustrates the editing process of the beginning of the third stanza of the famous eulogy of Haoma (Yasna 9,3), the intoxicative drink used in Zoroastrian ritual. We have to start from the transliteration of the manuscript variants of the text in order to establish one reading text with a critical apparatus (cf. above Slide 4). In this example, the manuscripts J2, K5 and Mf4 represent an independent branch each, whereas R413 is a copy of Mf4 exhibiting no important variants except mistakes made by the scribe. The text edition can be given in transliteration or in original script using standard glyphs defined as a result of the script evaluation process. A transliterated edition, however, alongside of a photograph of the original manuscript is more suitable for scientific purposes because it depicts and describes more precisely the script data.
A transcription of an Avestan text presupposes and implies a certain linguistic analysis of the
language data. It is rather difficult to reconstruct the phonemic units the phonetic notation of the
priests is based upon. Consequently, we can never dispense with transliterated texts when handling
the Avestan documents. Translation and interpretation of the meaning conveyed by the Avestan
texts is even more complex because of their mystic nature. Like this, the contribution of historical
and comparative linguistics to the explanation of these important documents is all the more
indispensable since comparative evidence only can elucidate phaenomena that remain obscure when
considered from the internal, i.e. Iranian, viewpoint.
8. Text retrieval
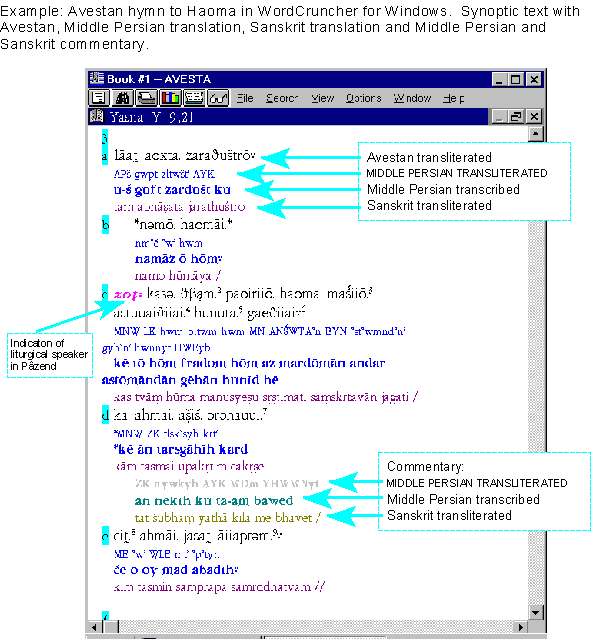
This slide continues the discussion of Avestan text edition, exposing its transfer into an Hypertext environment. The retrieval engine the TITUS project uses is WordCruncher, a product of Brigham Young University (Utah). The window shows the text of the hymn to Haoma: the transliterated Avestan text is alligned with the Middle Persian translation given both in transliteration and transcription, and with the Sanskrit translation. The lines differ in color and font style. A double click on a word (Avestan, Middle Persian or Sanskrit) prompts a Reference Window offering all occurrences in the whole text corpus. TITUS built indexes of all three text versions so that the secondary renderings are available as well: investigations on the semantics of Avestan words and phrases have to consider these early interpretations. Again different text colors mark the interspersed Middle Pesrian and Sanskrit commentaries.
The manuscript tradition can be displayed in a separate window so that the reading of each text document preserved is always available.
The WordCruncher Viewer is downloadable for free from the Wordruncher Web site: like this the indexes made by the TITUS project can be viewed and used wherever the viewer program and the special TITUS fonts are installed. Such an Hypertext edition of course marks the starting point of what could be called a text laboratory. In the future we will construct Web pages where every scholar is able to contribute his own opinion about the establishment of the reading text and the evaluation of manuscript variants.
When Unicode will comprise the Avestan script, the electronic administration of this Old Iranian
memory can finally be carried through without encoding ambiguity.
 9. Bibliographic information server
9. Bibliographic information server
 With the development of the WWW collecting scientific bibliography must become a
communicative work. The TITUS project decided to open its bibliographic database for worldwide
participation. This pressuposes an interactive interface: Choosing "Bibliographia" from the TITUS
start page buttons you arrive at the relevant section of the server. On the bottom of the page you
follow the links in order to get the entering form for bibliographic data. Whoever published
scientific work in the field of historical and comparative linguistics or in a neighbouring area can
enter the informations due. Third party communications are possible as well. The entries then are
verified by the operators of the bibliography server who will contact the author or the contributor in
case there are questions left unanswered.
With the development of the WWW collecting scientific bibliography must become a
communicative work. The TITUS project decided to open its bibliographic database for worldwide
participation. This pressuposes an interactive interface: Choosing "Bibliographia" from the TITUS
start page buttons you arrive at the relevant section of the server. On the bottom of the page you
follow the links in order to get the entering form for bibliographic data. Whoever published
scientific work in the field of historical and comparative linguistics or in a neighbouring area can
enter the informations due. Third party communications are possible as well. The entries then are
verified by the operators of the bibliography server who will contact the author or the contributor in
case there are questions left unanswered.
The current character processing abilities, however, impose considerable restrictions upon the transfer of bibliographic data, particularly in the context of historical and comparative linguistics where authors names, publication titles and other informations normally contain special characters. Except ISO 8859-1 there is no standard character set that every operating system is able to unterstand unambiguously. Consequently, TITUS had to define an 8-bit gate in order to avoid unrecoverable loss of information. Special characters outside ISO 8859-1 must be encoded by ASCII character sequences according to the prescriptions given on the introducing page: ASCII symbols and punctuation signs are assigned to diacritics; the handling of Ancient Greek language data follows the convention of Beta code, used by the Thesaurus Linguae Graecae project.
It is self-evident that only a Unicode conformant operating system as well as Unicode compatible data transfer via appropriate translation filters will provide an adequate environment for the TITUS bibliography server and similar projects elsewhere. In this field we will of course closely cooperate with libraries and archives applying a Unicode conforming data management. As far as diacritics for use in scientific transliteration and transcription are concerned, we will have to propose an supplementary set of modifier letters and combining diacritical marks for inclusion into Unicode since we need more code places in order to administer these very complex data: glyph standardization only cannot guarantee unambiguous processing.
After having studied the entering instruction the contributor chooses a form corresponding to the publication category: monograph, journal article, etc. Within the form, the entry can be assigned to the languages and language families listed in the pop-up menus.
10. Conclusion
Browsing the memory of the world will be an internet facility all civilizations of the world should profit from. Unicode can provide the presuppositions for a powerful character processing including the historical scripts. In this way the written documents of the past will be easily accessible and will help to maintain civilization identity and a free development of cultural life.
Presenting the TITUS project at an International Unicode Conference aims at a better understanding of the new possibilities introduced by the WWW as well as the difficulties involved. Preparing the memory of the world to be exposed on the Web is the task of the international scholarly community. TITUS is one of the cooperation pools the relevant scientific disciplines dispose of. I hope that my paper demonstrated how scientific work on the ancient documents now becomes a communicative process via the WWW, whereas in former times these activities did not leave a certain working place, an institute or a scholar's study, except by means of printed reports and text editions that for technical reasons could never provide the totality of the material dealt with, especially a photographic documentation. The TITUS Ogam server represents the new generation of an internet edition of ancient texts.
TITUS will progress rapidly. The text database will change its structure to become a text laboratory, the ancient documents being indexed and integrated into an Hypertext system. Discussion on the editing problems will take place on the Web as soon as more operating systems, applications and typeware will be Unicode aware and more historic scripts will have been included into the standard.
Naturally, the TITUS project is an ideal forum for the preparation of encoding proposals for historic scripts. We would like to address the best specialist for every script that belongs to our domain but also to an area outside Indo-European. We are ready to bring to bear all our experience in electronic processing of historical language data, in order to assist the Unicode New Script Committee when historic scripts are to be evaluated and, after the inclusion process, to be described in the Unicode documentation.
Scientific work on the memory of the world, however, cannot be done without sufficient funding by the supporters of universities and other scholarly institutions. We invite computer industry as well to engage in preserving the memory of the world!