|
Thesaurus Indogermanischer Text- und Sprachmaterialien
|
| TITUS |
UNICODE |
Titus Is Testing Unicode Scriptmanagement
Treatment of Diacritics in Unicode
This page is designed to help people who intend to use Unicode encoding
for scripts containing combinations of basic characters with diacritics. It
will help them to find out whether a given combination is encoded in Unicode 2.1
as a "precomposed character" or not, and if not, whether it has been stored
in the TITUS collection of diacritic combinations not present in Unicode.
Below, you will find tables of
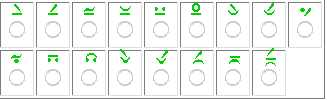
Latin,
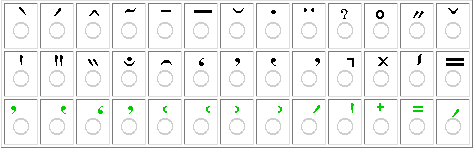
Greek,
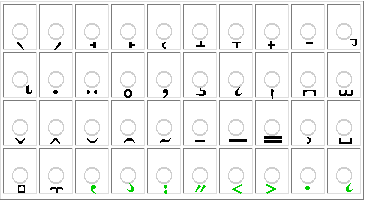
Cyrillic, and
Georgian
characters together with tables containing diacritics that might be used in
combination with them. By clicking
- first on one of the basic characters,
- then on at least one of the diacritics shown,
you will cause a script to check whether the combination you chose is encoded
in Unicode or whether it has been stored in the TITUS collection. The result
will appear either in the bottom frame of this window (if your browser is
able to display frames) or in an extra window.
If you intend to check a combination containing of more than one diacritic,
please be sure to click the diacritics in the order recommended by Unicode,
viz. starting with the one which is nearest to the top of the basic character,
continuing upward with superscript diacritics, then starting with the one
which is nearest to the bottom of the basic character and continuing downward
with subscript diacritics.
If the combination you entered is present in Unicode 2.1 or in the TITUS
collection, the result will be displayed in the following form:
| |
58405 |
E425 |
LATIN SMALL LETTER A WITH DOUBLE ACUTE ABOVE |
0061+030B |
a̋ |
The diagram contains the following information:
- :
- The combination you chose, encoded
as a precomposed character. If the character is displayed in green,
it is not encoded as such in Unicode 2.1 but is included in the TITUS collection.
In this case it will only be displayable if you have installed the
TITUS Unicode font.
- E425:
- The Unicode number (in hexadecimal form) of the precomposed
character. If the number begins with E or F, the character is not part of Unicode
2.1 proper but treated as part of the "user definable area" within Unicode.
In this case, the number is proposed by TITUS for further treatment.
- 58405:
- The same number as above, in decimal form.
- "LATIN SMALL LETTER A WITH DOUBLE ACUTE ABOVE":
- The name of the combination
you chose. If the combination is not present in Unicode 2.1, this will be a
name proposed by TITUS for further treatment.
- 0061+030B:
- The respective Unicode numbers (in hexadecimal form) of the
basic character and the diacritic(s) involved.
- a̋:
- The combination you chose, encoded as a sequence of the basic
character and the diacritic(s) contained. According to the prescriptions of
Unicode, the placement of the diacritic(s) should be as correct as in a
precomposed character, but this effect is not guaranteed by any operating
system that can handle Unicode encoding nowadays. The combination may only
be displayed with all its part if you have installed the
TITUS Unicode font. Please note
that some diacritics are not present in Unicode as such.
If the combination you entered is not present in either Unicode 2.1 nor in
the TITUS collection, an error message will appear instead.
In near future, this will be substituted by a form where you can enter
detailed information about the character you checked, in case you want this
character to be stored in the TITUS collection for further treatment,
esp. with respect to providing a proposal for a Unicode extension.
�
Latin characters with diacritics:
�
Greek characters with diacritics:
�
Cyrillic characters with diacritics:
�
Georgian characters with diacritics:
Back to the TITUS homepage
Copyright of this page: Jost Gippert, Frankfurt a/M, 3.9.1999.
No parts of this document may be republished in any form without prior permission by the copyright holder.