| Achtung: Dieser Text ist mit Unicode / UTF8 kodiert. Um die in ihm erscheinenden Sonderzeichen auf Bildschirm und Drucker sichtbar zu machen, muß ein Font installiert sein, der Unicode abdeckt wie z.B. der TITUS-Font Titus Bitstream Unicode. | Attention: This text is encoded using Unicode / UTF8. The special characters as contained in it can only be displayed and printed by installing a font that covers Unicode such as the TITUS font Titus Bitstream Unicode. |
III. ზმნის კომპიუტერული ანალიზისა და სინთეზისათვის
უდიურში
ა) ზმნის ზოგადი მორფოსინტაქსური დახასიათება. ზმნის
უღვლილება დაღესტნურ ენებში ამ ენათა მორფოლოგიის არსებით
თავისებურებას ქმნის - დაღესტნურ ენებში ზმნა კლასოვანი
უღვლილებისაა. ამ თვალსაზრისით გამონაკლისს წარმოადგენს
უდიური, ლეზგიური, აღულური და ნაწილობრივ თაბასარანული.
ზმნის უღვლილება უდიურში მონოპერსონალურია: მხოლოდ
სუბიექტი არის მარკირებული ზმნაში. ამ თვალსაზრისით უდიური
ზმნის მოდელირება ქართული ენის პოლიპერსონალური ზმნის
მოდელირებასთან შედარებით ნაკლებ სირთულეებთან არის
დაკავშირებული. სამაგიეროდ სხვა სახის სირთულეები გვხვდება აქ.
უპირველეს ყოვლისა, მხედველობაში გვაქვს პირის ნიშანთა რანგის
საკითხი, რასაც ართულებს პირის ნიშანთა სერიების არსებობა და
ზმნის სინტაქსური კონსტრუქციების მრავალფეროვნება.
ზმნაში სუბიექტის აღსანიშნავად უდიურ ენაში გამოყენებულია
პირის ნიშანთა სამი სერია, რომლებიც ისევე, როგორც კავკასიურ
ენათა უმეტეს შემთხვევაში, ნაცვალსახელური წარმოშობისანი
არიან. ამასთან, პირველი სერიის პირის ნიშნები შეესაბამებიან
პირის ნაცვალსახელის სახელობითი ბრუნვის ფორმას, მეორე სერიის
პირის ნიშნები - მიცემითი ბრუნვის ფორმას, ხოლო მესამე სერიის
პირის ნიშნები - ნათესაობითი ბრუნვის ფორმას.
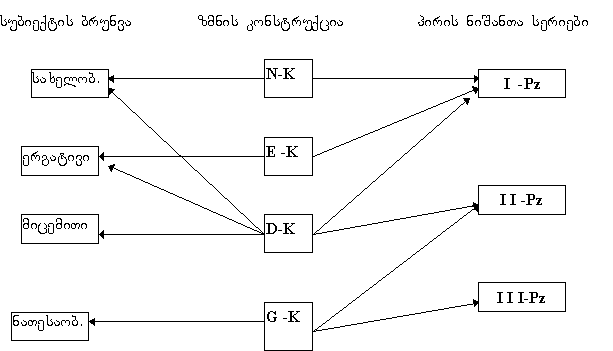
სინტაქსურ კონსტრუქციათა თვალსაზრისით კავკასიურ ენებში
განარჩევენ ზმნის ოთხი სახის კონსტუქციას: ნომინატიურ
კონსტრუქციას (N-K), ერგატიულ კონსტრუქციას (E-K), დატიურ
კონსტრუქციას (D-K) და გენეტიურ კონსტრუქციას (G-K). ამასთან,
გარდამავალი (აგენტური) ზმნები ერგატიულ კონსტრუქციას
გვიჩვენებენ, გარდაუვალი (ფაქტიტიური) ზმნები ნომინატიური
კონსტრუქციით გვხვდებიან.
აფექტურ ზმნათა ჯგუფი (verba sentiendi) “ინვერსიულ” ანუ
დატიურ კონსტრუქციას იყენებს, მცირედ წარმოდგენილი “პოსესიური”
ზმნები (verba habendi) კი გენეტიური კონსტრუქციისაა.
დასახელებული ზმნური კონსტრუქციებიდან უდიურში ოთხივე
დასტურდება, ოღონდ ერთი თავისებურებით: როგორც გარდამავალი
(ერგატიული კონსტრუქციის), ისე გარდაუვალი (ნომინატიური
კონსტრუქციის) ზმნის სუბიექტი I სერიის პირის ნიშნებით არის
მარკირებული ზმნაში.
ასიმეტრიულობა ზმნურ კონსტრუქციათა, პირის ნიშანთა
სერიებისა და ზმნის მიერ მართული სუბიექტის ბრუნვათა
ურთიერმიმართებათა თვალსაზრისით ასახულია ცხრილში:
| ზმნის სინტაქსური კონსტრუქცია | პირის ნიშანთა სერიები | სუბიექტის ბრუნვა |
| ნომინატიური | I (N/E-Pz) | სახელობითი |
| ერგატიული | I (N/E-Pz) | ერგატივი |
| დატიური | II / I (D-Pz) / (N/E-Pz) | მიცემითი||ერგატივი |
| გენეტიური | III / II (G-Pz) / (D-Pz) | ნათესაობითი |
უდიური ზმნის შემთხვევაში შეუძლებლად მიგვაჩნია რანგის
თეორიის პრინციპების გამოყენება როგორც პირის ნიშნის რანგის,
ისე ზოგადად სტრუქტურულ ელემენტთა რანგირებისათვის. ამიტომ,
ჩვენი უშუალო მიზნებიდან გამომდინარე, კომპიუტერული
მოდელირებისათვის ვიყენებთ სტრუქტურულ მოდელებს, რომელშიც
ელემენტთა რანგი განისაზღვრება არა მისი ტრადიციული გაგებით
(ფუძიდან დაშორება წინამავალ ელემენტთა გათვალისწინებით),
არამედ უშუალო სტრუქტურულ შემადგენლებად დაშლის შემდგომ მისი
ადგილის (თანმიმდევრულობის გათვალისწინებით მარცხნიდან
მარჯვნივ) მიხედვით. ამასთან, ფუძე აღინიშნება არა ნულოვანი
რანგით, როგორც ეს რანგის თეორიაში არის მიღებული, ხოლო
მორფემები ±R ფუძიდან მაქსიმალური დაშორების მიხედვით, არამედ
განიხილება სტრუქტურულ ელემენტთა ცალმხრივი თანმიმდევრულობის
მარტივი წესით: უკიდურესი მარცხნიდან უკიდურესად მარჯვნივ.
უდიური ზმნის ფუძე შეიძლება იყოს მარტივი ან რთული
აგებულების. კომპონენტური შედგენილობის თვალსაზრისით თუ
განვიხილავთ, ზმნათა შემდეგი ტიპები გამოიყოფა: (A)
ერთკომპონენტიანი (V1=Kv) და (B) ორკომპონენტიანი (V2=Kn + Kh).
ერთკომპონენტიან ზმნებში უნდა გამოვყოთ ზმნები (A1) პირველადი
(Vv=St + IM) და (A2) ნაწარმოები (Vv=St1 + St2 + IM) ძირით.
პირის ნიშნები როგორც ერთკომპონენტიან, ისე
ორკომპონენტიან ზმნებში ინფიგირებულია. პირის ნიშანთა
განაწილების შემთხვევები რომ შევაჯამოთ, პირის ნიშანთა
რამდენიმე რანგი უნდა გამოვყოთ: r1, r2, r3, r4.
უდიური ზმნის ზოგად სტრუქტურულ-ფორმალურ მოდელში
S = {(Stamm), (Kk)}
სადაც Stamm = {(St1+St2), (Kn+Kh)}
Kk = (Ks; Kv)
პირის ნიშანი (ცალკე ან უარყოფის / კაუზაციის ნიშანთან
ერთად კომბინაციაში) ავლენს ტენდენციას:
(1) ინფიქსის სახით ჩაერთოს ძირეულ მორფემაში
(სეგმენტირებად ერთკომპონენტიან და ორკომპონენტიან ფუძეებთან);
ამასთან r2 მეორე (მორფემულ) ელემენტად დადებით / არაკაუზაციურ
ფორმებში, r3 -უარყოფით, r4 - კაუზაციურ (მეორადი კაუზაციის)
ფორმებში;
(2) სუფიქსის სახით რეალიზდეს, თუ ძირეული მორფემა
არასეგმენტირებადია (სტატიკური ზმნების შემთხვევაში), აგრეთვე
გარკვეულ სინტაქსურ გარემოცვაში;
(3) პრეფიქსის სახით რეალიზდეს, (მაგ. ნიჯურ დიალექტში) - r1.
პირის ნიშანთა განაწილების ზოგადი სურათი რანგების
მიხედვით მოცემულია F ცხრილში.
ცხრილი F
| ზმნის სტრუქტურული მოდელები | r1 | r2 | r3 | r4 | r5 | r6 | |
| 1 | Pz + Pr | ზახ | პუ | ||||
| 2 | Pr + Pz N + Pz + St + T Kn + Pz + Kh + T St1 + Pz + St2 + I + T N + Pz + Kn + Kh + T | ჩურფი თე აშ ბა თე | ნე ნე ნე ნე ნე | ბეს ბს ქ აშ | ა ა ს ბეს | ა ა | |
| 3 | Kn + Pl + Pz + Kh + T Kn + N + Pz + Kh + T Kn + Ks + Pz + Kh + T Kn + Kh + Pz + Kv + T N + Pl + Pz + Pr | ქარ ცამ ბათ ჭევ მა | ყა თე ევ კეს ყა | ნ ნე ნე ნე ნ | ხ ეხ კს სტ თაცი | ი ა ა ა | |
| 4 | Kn + T + N + Pz Kn + Ks + Kh + Pz + Kv + T | ბეს ბათ | ა ევ | თე კეს | ნე ნე | სტ |
|
პირის ნიშანთა განაწილების სურათი კიდევ უფრო გართულდება,
თუ მას უღვლილების მთელი სისტემის ფარგლებში განვიხილავთ.
ქვემოთ მოცემულ ცხრილში შეძლებისდაგვარად ასახულია სხვადასხვა
მწკრივებში როგორც პირის ნიშნის განაწილების ვარიაციულობა, ისე
ზმნის სტრუქტურული მოდელები.
ცხრილი G

| საყრდენი ფუძე | საყრდენი მწკრივი | ნაწარმოები მწკრივი | ნაწარმოები მწკრივი | |
| I | ინფ-მასდარი | აწმყო | ნამყო უწყვეტელი | |
| II
a b | მიმღეობა (ექსტემპორ.) მიმღეობა (აწმ.-მყოფ.) | აორისტი I მყოფადი I | ნაწ.
კავშირებითი I ნაწ. კავშირებითი II ნაწ. მყოფადი | |
| III | ნეიტრალური ფუძე | აორისტი II | ბრძანებითი კავშირებითი I მყოფადი II | აწმ. კავშირებითი III |
ბ) ზმნის კომპიუტერული მოდელირებისათვის.
C = (C1, C2, C3)
სადაც C1 = N-Stamm
C2 = I-M
C3 = Pr
დრო-კილოთა პირველ ჯგუფში გაერთიანებულ მწკრივთა
პარადიგმები იწარმოება C2 კონსტანტაზე დაყრდნობით, მეორე
ჯგუფში გაერთიანებული მწკრივები - C3, ხოლო მესამე
ჯგუფში გაერთიანებული მწკრივები - C1 კონსტანტაზე
დაყრდნობით.
| ჯგუფი | კონსტანტის სახე | ფუძის სტრუქტურა A | ფუძის სტრუქტურა B |
| I | C2 | ბაქეს / ბაქსუნ | აშ-ბეს / აშ-ბესუნ |
| II | C3 | ბაქი, ბაქალ | აშბი, აშბალ |
| III | C1 | ბაქ | აშბ |
ცვლადების სიმრავლეს ქმნის პირის ნიშნები, დრო-კილოთა
მაწარმოებელი აფიქსები, ნაწილაკი, უარყოფის ელემენტი,
კაუზაციის მორფემა:
Var = (Pz, Pl, Ks, N, T)
ზმნის პარადიგმის (P) ფორმალური მოდელის ასაგებად
განისაზღვრა პარადიგმის პარამეტრები:
P = (P1, P2, P3, P4, P5, P6)
სადაც P1 - ზმნის სინტაქსური კონსტრუქცია
P2 - ფუძის სტრუქტურის პარამეტრი
P3 - ფუძის ხასიათის პარამეტრი (C)
P4 - პირის ნიშნის პარამეტრი
P5 - მწკრივის მაწარმოებელ მორფემათა
განმსაზღვრელი პარამეტრი
P6 - კაუზაციის პარამეტრი
ამასთან,
P1 = V-K (N-K; E-K; D-K; G-K)
ფუძის სტრუქტურის პარამეტრი
P2 = (An; Bn)
ფუძის ხასიათის პარამეტრი
P3 = (N-Stamm, I-M, Prm)
m є (E.-T. Pr; P.-F.Pr)
ამასთან P3 = F (P2);
პირის ნიშნის პარამეტრი
P4 = Pz{(I-Pz)n, (II-Pz)n, (III-Pz)n}
სადაც (I-Pz)n = n(S1, S2, S3, Pl1, Pl2, Pl3)
ამასთან P4 =P1(P1 (V-K))
სადაც V-K = { N-K, E-K, D-K, G-K }
ზმნის სინტაქსური კონსტრუქციისა და პირის ნიშანთა სერიების
ურთიერთმიმართება P4 = P1 (V-K) მოცემულია ცხრილში:
| ზმნის სინტაქსური კონსტრუქცია | პირის ნიშანთა სერიები | ||||||||
| V-K | Pz
| N-K | I (N/E-Pz)
| E-K | I (N/E-Pz)
| D-K | II / I (D-Pz) / (N/E-Pz)
| G-K | III / II (G-Pz) / (D-Pz) | |
მწკრივის მაწარმოებელ მორფემათა განმსაზღვრელი პარამეტრი
P5 = T (t1, t2,t3,...,tn)
კაუზაციის პარამეტრი
P6 = (Ks; Kv)
ამასთან Ks - -ევ-
Kv - დესუნ
ზმნის პარადიგმის (P) პარამეტრების განსაზღვრისა და შესაბამისად
მორფემული ინვენტარის აღწერის შემდეგ შევეცდებით ზმნის
მოდელირებას მწკრივების მიხედვით. ამასთან, თუ ზემოთ მოცემულ
მსჯელობებსა და შესაბამის ცხრილებში ზმნის სტრუქტურა და
შესაბამისად, მორფემათა რანგი განიხილებოდა ზმნის სრული
სეგმენტაციის საფუძველზე, ქვემოთ შევეცდებით გავითვალისწინოთ
მწკრივის წარმოების არსებითი პრინციპი და როგორც მოდელირების,
ისე მწკრივის ფარგლებში ზმნის სტრუქტურული ელემენტების რანგის
განსაზღვრისას დავეყრდნოთ კონსტანტისა და ცვლადის ცნებებს.
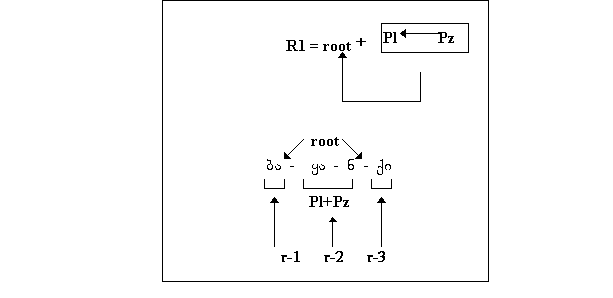
ზმნის უღვლილებისათვის გვაქვს ერთი მხრივ კონსტანტა, ანუ
მწკრივის საყრდენი ფუძე root, მეორე მხრივ, ცვლადი ანუ მწკრივის
ნიშანი t. კონსტანტისა და ცვლადის კომბინაცია ქმნის მწკრივის
ფუძეს R1.
R1 = root + t
root = (A; B)
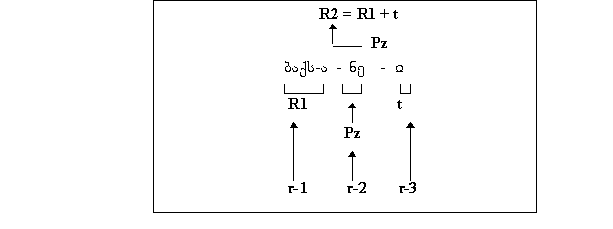
მეორადი წარმოების შემთხვევაში მოცემული მწკრივის ფუძე R1
საყრდენ ფუძედ, კონსტანტად გამოიყენება სხვა მწკრივისათვის.
ასეთი მეორადი წარმოების მწკრივში ზმნის სტრუქტურული მოდელი
მიიღებს შემდეგ სახეს:
R2 = R1 + t
R2 = (root + t) + t
ამდენად, ერთმანეთისაგან განვასხვავებთ პირველადი და მეორადი
წარმოების მწკრივებს. პირველადი წარმოების მწკრივებში ზმნის
სტრუქტურული მოდელია R1 = root + t, მეორადი წარმოების მწკრივებში
კი R2 = R1 + t.
პირის ნიშანი უდიურში ავლენს ტენდენციას რანგის თვალსაზრისით
მეორე ადგილი დაიკავოს ზმნის სტრუქტურაში, მაგრამ სხვადასხვა
ვარიაციით.
(ა) პირის ნიშანი კომბინირებს R1-თან. ასეთ შემთხვევაში გვაქვს
ზმნური მოდელი (1);
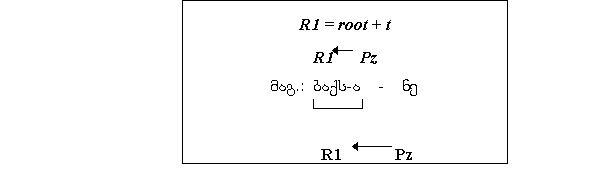
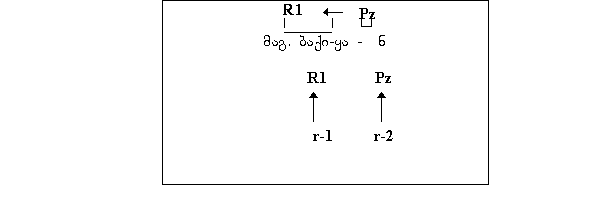
ამასთან, პირის ნიშნის რანგია r-2 და იგი რეალიზდება სუფიქსის
სახით. ამ მოდელის მიხედვით იუღვლება ზმნა I და II ჯგუფის
პირველად მწკრივებში (აწმყო, აორისტი I, მყოფადი I) და III
ჯგუფის ყველა პირველად მწკრივში.
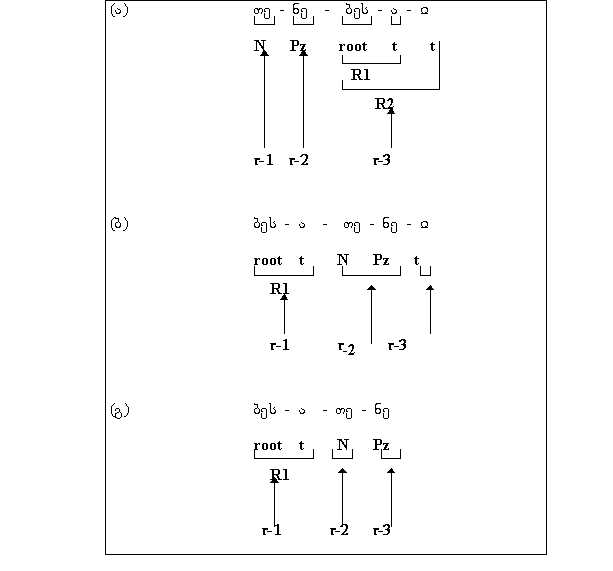
(ბ) პირის ნიშანი კომბინირებს root -თან, ჩაერთვის მას მეორე
ელემენტად და ასეთ შემთხვევაში გვაქვს ზმნური მოდელი (2ა) ან
(2ბ):

(გ) პირის ნიშანი კომბინირებს R2-თან, ჩაერთვის მას მეორე ელემენტად და ასეთ შემთხვევაში გვაქვს ზმნური მოდელი (3):
R1 = root + Pl
ან (4ბ) მოდელი; ამასთან, პირის ნიშანი ნაწილაკთან
კომბინირებს და მასთან ერთად ბლოკის სახით ჩაერთვის root-ს.
R1 = root + Pl
პირის ნიშნის ნაწილაკთან (რანგის თვალსაზრისით) ერთ ბლოკში
გაერთიანების საფუძველს ის გარემოებაც გვაძლევს, რომ
უარყოფით ფორმებში უარყოფის ნაწილაკი უშუალოდ პირის ნიშანს
ჩაერთვის წინ და მასთან ერთად რეალიზდება (ა) პრეფიქსული,
(ბ) ინფიქსური ან (გ) სუფიქსური ბლოკის სახით:
(ა) N - Pz - R2
(ბ) R1 - (N+Pz) - t
(გ) R1 - (N+Pz)
ტექსტის კომპიუტერული დამუშავების დროს ზმნის კომპიუტერული ანალიზი ხორციელდება სამ ეტაპად: (1) შერჩეული სიტყვაფორმის მარკირება; (2) ზმნის პარამეტრთა გამოყენებით საანალიზო სიტყვაფორმის დაშლა შესაძლო მორფემებად და მისი ვერიფიკაცია უდიური ენის მონაცემთა ბაზასთან: კერძოდ, უდიური ენის მონაცემთა ელექტრონულ ლექსიკონთან მიმართების გზით, ერთი მხრივ და ატრიბუტთა რეესტრის იდენტიფიკატორების გამოყენებით, მეორე მხრივ, ხორციელდება შესაბამისად სეგმენტირებულ მორფემათა იდენტიფიკაცია; (3) თუ სეგმენტირების შედეგად მიფებული ფუძე მონაცემთა ბაზაში არ აღმოჩნდა, მიმდინარეობს ტექსტში ყველა იმ სავარაუდო სიტყვაფორმის მარკირება სელექციის გზით, რომელიც იდენტიფიცირებული ფუძის უღლების პარადიგმის შესაძლო წევრად ივარაუდება.