Unicode, Ancient Languages and the WWW
Carl-Martin Bunz, M.A.
Universität des Saarlandes, Saarbrücken, Germany
Prof. Dr. Jost Gippert
Johann Wolfgang Goethe-Universität, Frankfurt/M., Germany
0. Herodotus, the famous Greek historian of the fifth century B.C., reports how the Greeks
took over and adapted the Semitic alphabet:

"These Phoenicians who had arrived together with Cadmus -- of whom the
Gephyraeans were a part -- after having settled in this country, imported many
kinds of learning to the Greeks and especially characters which, as I think, the
Greeks had not before -- first those (characters) that all the Phoenicians used.
Afterwards, as time went on, simultaneously with the change of language, they
altered also the shape of the characters. At this time, in many of the places
around them the Ionian Greeks were dwelling who, after having been taught by
the Phoenicians, took over the characters, modified few of them in shape and
used them. In doing so they spoke of them by the name of Phoenician -- as
indeed was but just, seeing that the Phoenicians had introduced (the
characters)."
We shall not discuss the historical correctness of Herodotus' record: His account of the
transfer of a Semitic script to early Greece is essentially right. The import of this writing
technique -- which was not the first one used for the notation of Greek -- was to entail
enormous consequences; if it had not taken place, the world would probably not have seen the
development of the Latin alphabet and its wide proliferation. By these few sentences
Herodotus describes the process of script adaptation which many language communities before
and after the historian's time performed. There is an ethnic group that settles in an foreign
country; they bring with them their language and their writing system, using a certain script.
Later on, they adopt a different language and adjust the repertoire of symbols their script
disposes of. Further, there is another language community dwelling in the neighbourhood that
is taught this script by those who first practised this method of writing, and again adjustments
of the symbols used are necessary. But the character set, although modified by the transfer
from one community to the other, is given the name of those who first introduced and taught
its usage.
Herodotus, however, does not explain the crucial point of the change the Semitic inventory of
consonant symbols underwent when it was adapted to the notation of Greek. The Semitic
script units operate as symbols of syllabic classes, whereas in Greek the first attempt was
made to represent in writing what we today call phonemes, when the adaptors defined vowel
symbols.
Writing now has a long history, its dissemination and diversification exactly in the way
Herodotus describes is considerable seeing that there are but a few original notation principles
of language data, i.e. ideographic, syllabic and alphabetic writing. Language communities all
over the world developed writing systems making use of one or more of these principles.
Nevertheless, in most areas one writing system prevailed.
Those language communities of the past that used writing recorded what was important for
them in daily life, but also contents they regarded as worth conserving for later generations,
such as legal and religious texts. The material they wrote on, the climate and the political
history of the region decided upon the preservation of these documents. The textual monuments
which survived since man first developed writing at about 3000 B.C. constitute in their
entirety the world's memory of civilization: Sumerian agricultural records and religious
poetry, a Maya calendar, reports of Hittite kings, the liturgical texts of the Zarathustrians, etc.
etc.
Historical and comparative linguistics provides the scientific basis for a linguistic analysis and
understanding of these texts. Furthermore comparative linguistics interprets the linguistic data
and determines the genetic relationship between the languages as well as between different
historical stages of one language. Like this, comparative linguistics traces the history of
human verbal expression.
A 16-bit encoding space is necessary at least for parallel processing and transfer of linguistic
data using distinct encodings for different scripts. We do hope that, within the WWW,
comparative linguistics will soon be able to supply the ancient texts in electronic form --
alongside with comprehensive philological and cultural information -- so that the scientific
and scholarly community as well as everyone else interested in the matter can explore the
memory of the world, provided a worldwide character encoding system exists that supports
historical data as well as national and commercial standards.
Unicode, the Worldwide Character Encoding, primarily represents a standard designed as to
process the scripts of the major modern languages of the world, on the basis of the norms
national ISO commissions elaborated. Like this, the architecture of the encoding is based on
synchronic scripts. On the other hand, since the publication of Unicode Standard Version 1.0
the designers of the encoding maintain that historic scripts will be included as well. But as
soon as historic scripts are considered the historic development of the scripts has to be taken
into account as well. This is to say that the most important structural principle of the Unicode
architecture, the Character/Glyph Operational Model, must be open for a historic
interpretation too. Before having reconsidered the methodical impact that the encoding of
historic scripts bears, it is not very reasonable to simply integrate historic scripts into the
patterns the Unicode encoding strategy has established up to now.
First we have to see that administering the world's written memory of civilization does in no
way mean to establish norms or standards the establishment of which is often influenced by
extra-linguistic factors. Rather, we aim at preserving all the information that the ancient
records provide: When processing historic documents, we must never modify the script and
text data at our convenience. What we intend to demonstrate in this paper, is precisely the
challenge Unicode faces as soon as historic scripts will be taken into consideration. The flow
chart in Table 1 may give an idea of the constellation.
We hope to show up the difficulties in all their complexity and intertwinement that will arise
when Unicode is applied to historical data and to historical and comparative linguistics dealing
with them. Our presentation is meant to contribute to a discussion which in our view is really
necessary.
1. Let us enter again into the sphere of Herodotus, i.e. the emergence and further
development of the Greek script. More than 1000 years after its development from the Semitic
basis, the Greek script was borrowed by the Georgians and Armenians. Table 2 gives a
synopsis of these scripts; they are encoded in Unicode in the character blocks U+0530
U+058F and U+10A0 U+10FF respectively.
1.1.1. Like the Greeks of the archaic period, the inventor(s) of the Georgian Asomtavruli
alphabet on the one hand followed exactly the order of the model alphabet so as to keep the
numerical values of the characters, assigning to each graphical unit a similar phonetic value
in Georgian -- with a few exceptions where the Greek value had no correspondence in
Georgian. On the other hand he established an appendix of characters that represent phonetic
units alien to Greek, just as the Greeks themselves did before. In this appendix, the sequence
of characters reflects a specific articulatory organization. Like this, the Asomtavruli script
represents an alphabet which, although considerably differing in shape, is mapped perfectly
onto the model alphabet, with a number of additional units (cf. Table 2, fourth column).
In ancient Georgia, writing was practised exclusively for clerical purposes. Asomtavruli as a
monumental script was designed for inscriptions first (cf. Table 3), but later on it was used in
manuscripts too (cp. e.g. the lower text of the palimpsest manuscript reproduced in Table 4).
By the eighth century A.D. the scribes began to style larger letters to mark the beginning of
paragraphs, and so they introduced the minuscule-majuscule distinction into the writing
system. Consequently, in the course of the ninth century, a half-cursive script variant was
derived from the Asomtavruli minuscule characters, later named Nusxa-Xucuri (cp. the third
column in Table 2 and the upper text of the palimpsest in Table 4). In the tenth century A.D.
an other important change happened in Georgian writing: now Mxedruli, the proper cursive
script variant, was developed especially for secular use (cf. the second column in Table 2). At
that time, the Georgian script system had attained its greatest complexity: In manuscripts we
find Asomtavruli characters operating as uppercase letters alongside with Nusxa-Xucuri
characters, while "colophon" notes were often written in Mxedruli; but only in the 20th
century Asomtavruli letters were used as Mxedruli "majuscules". This attempt of calquing
European writing usage was introduced by Georgian scholars only and it had no impact on
everyday's use.
From all this we conclude that the encoding of Georgian as present in the Unicode block
U+10A0 -> U+10FF (cf. Figure 1) is not sufficient when handling historic texts written in that language,
the block containing Asomtavruli (U+10A0 -> U+10C5) and Mxedruli (U+10D0 ->
U+10F6) characters only. The script variant Nusxa-Xucuri must be encoded as well because,
as was shown above, the three scripts were clearly distinguished in their application during
the history of Georgian writing, existing side by side for a long period. Working with the
Unicode Georgian character block in its present form would mean, e.g., to encode an ancient
inscription (like the one printed in Table 3) or an ancient manuscript with the Mxedruli
characters, the Asomtavruli script units being glyph representations of these code elements;
the Asomtavruli characters of the Unicode block would have to be reserved for majuscule
forms of Asomtavruli letters instead (cf. Figures 3, 4, 5).
The situation becomes even more complex when we
want to encode a document that contains all three scripts, as described above. This is why we
propose to establish three character blocks for Asomtavruli, Nusxa-Xucuri and Mxedruli
respectively, each block comprising (Asomtavruli) majuscule characters.
1.1.2. The Armenian script had also been drawn up on the model of the Greek alphabet and
so it can be mapped onto the original to a certain extent too, although the shapes of the
matching Armenian letters are altered to an even higher degree than in the Asomtavruli
alphabet. But the designer of the Armenian script did not aim at aligning the numerical values
of the characters with those of the Greek patterns (rather he even aimed at establishing
differences as to the Greek series). Interspersing all the additional characters between the
characters inherited from the Greek stock, he established a new sequence so that a mapping of
the complete Armenian alphabet on Greek is not possible. Like this, a sharp difference arose
between the Armenian and Georgian scripts in that the latter only could be treated as glyph
variants of the Greek alphabet in Unicode. In this sense Georgian behaves just as Coptic does
which has in fact been integrated as an extension of Greek (U+0370 U+03FF).
1.2. Up to this point, we have considered the processing of original scripts. Now we should
like to enter into the issue of transliteration and transcription. In order to avoid misunderstandings, let us first state how we interpret what we shall call `transliterative processing' and
`transcriptive processing' with respect to Unicode characters. This presupposes that we define
clearly what we are doing when handling linguistic material.
Linguistic transliteration and transcription are strategies that aim at rendering language data
by mostly Latin letter forms in order to achieve a common notational level which enables
analysis and comparison of the data. Greek letters and modifications of Latin letters are also
used. Most of these signs are modified by diacritics marking additional distinctions the simple
letter forms are not able to convey. The difference between both strategies can then be
described as follows:
Transliteration is a method of miming original scripts with the help of
symbols as described above. This miming pertains to the graphical units the
script uses, without regard of their functional (i.e. phonetic) value. In certain
cases, miming may even extend to iconic imitation when e.g. the form of a
diacritic mimes a graphical element that belongs to the original script.
Transcription is a method of rendering the original script after a graphemic
and phonemic analysis of the linguistic data involved. That is, transcription
presupposes a functional interpretation of the material. Therefore, transcription
normally uses fewer graphical units than transliteration and is totally
independant from graphical shapes of the original script.
Both strategies are indispensable in linguistic work. Especially in the case of historic
languages, transliteration can be used to render the linguistic material as soon as the original
script has been segmented -- it does not presuppose, however, that the writing system in
concern has been fully understood. We represent linguistic data of dead languages in
transliteration in order to provide the data in a shape that is open for an interpretation aiming
at establishing the functional value of the graphical units as well as their phonemic and
morphemic values.
Transcription in its turn is a vehicle for transporting linguistic interpretations no matter
whether the scholarly community or part of this community agree upon this interpretation.
Phonetic transcription as normalized by the IPA must be kept apart from transliteration and
transcription as practised in historical linguistics, because the application of the well-defined
IPA symbols would demand an insight into the phonic reality of the ancient languages
involved. Although linguists often aim at establishing the phonetic system of ancient languages
in great detail, they will hardly be able to be as precise as linguists dealing with modern
languages. Historic transcription, however, aims at a level of phonic characterization that
leaves room for further investigation. Furthermore, the repertoire of IPA characters would not
suffice to mark the distinctions a specific transcription needs. If we applied IPA diacritics in
historical linguistics, we should introduce articulatory distinctions nobody can witness to --
and like this we should leave the area of scientific work. Within historical linguistics, phonetic
notation plays an important role only when the development of word forms in language
change has to be analyzed and demonstrated.
It is self-evident that both methods, transliteration and transcription, have to be encoded
unambiguously when linguistic data are stored and linguistic investigations are carried through
electronically. Now we try to transfer this constellation into the context of Unicode architecture:
A transcriptional system to represent a given writing system constitues a
writing system of its own right. In a Unicode conforming environment, a
transcription character set is made up by code elements, i.e. Unicode
characters, which are found mostly in the Latin Character Blocks of the
encoding, occasionally in other Character Blocks (Greek, Cyrillic). In analogy
with the processing of other latin-based writing systems, the Unicode
characters assume their specific semantics only within the transcriptional
system in question.
As for transliteration, there are two principally different ways it can be
handled using Unicode:
(a) Either a transliterational system of a given writing system is treated in the
way that it constitutes a writing system of its own right, exactly as a
transcriptional system does. A transliteration character set would then be made
up by code elements, i.e. Unicode characters (cf. above on transcription).
(b) Or transliteration, as opposed to transcription, can be considered as a glyph
representation of the original script.
Linguists will certainly favour the second solution which reflects the nature of transliteration
in an ideal manner. But such a method presupposes that the character blocks of the original
scripts do in fact exhibit all units required (cf. Figure 8).
After this theoretical excursus, let us return to Georgian and Armenian. We consider
Georgian first: In Table 2, the column exhibiting a Latin-based rendering of the Georgian
script units is labeled `Transcription' because the choice of a definite Latin character and a
definite diacritic presupposes a phonemic analysis of the language. When we transcribe, e.g.,
the affricates written 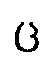 ,
, 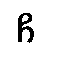 ,
, 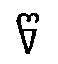 ,
, 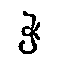 by the symbols c,
by the symbols c, 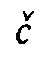 ,
, 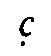 ,
, 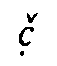 ,
a phonemic classification of the sounds
is implied, the diacritics representing articulatory features in a systematic manner. Thus, the
rendering is wholly independent of the shape of the original script units. The most effective
processing of Georgian transcription would be based on an exact correspondence of one
original script unit to one transcription unit each. Other solutions are more complex as they
require a one-to-n mapping.
,
a phonemic classification of the sounds
is implied, the diacritics representing articulatory features in a systematic manner. Thus, the
rendering is wholly independent of the shape of the original script units. The most effective
processing of Georgian transcription would be based on an exact correspondence of one
original script unit to one transcription unit each. Other solutions are more complex as they
require a one-to-n mapping.
Armenian is usually rendered by a transcription similar to the one used for Georgian, but it
differs in the method how certain articulatory features are marked by diacritics. In
transcribing Georgian stops and affricates, we mark the absence of aspiration, or the optional
presence of glottalization respectively (p 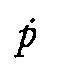 , t
, t
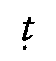 , k
, k 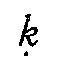 , c ,
, etc.); while in
Armenian, where the same phonemic functionality prevails, the presence of aspiration is
marked (
, c ,
, etc.); while in
Armenian, where the same phonemic functionality prevails, the presence of aspiration is
marked (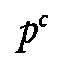 p,
p,
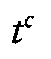 t,
t, 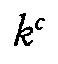 k,
k,
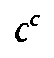 c,
c, 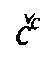
, etc.). When preparing Georgian and Armenian
transcription with the view to a Unicode conforming character processing, we should not,
however, level these transcriptional systems, because the difference of notation facilitates the
distinction of the language material concerned.
, etc.). When preparing Georgian and Armenian
transcription with the view to a Unicode conforming character processing, we should not,
however, level these transcriptional systems, because the difference of notation facilitates the
distinction of the language material concerned.
In the case of Georgian and Armenian, transliteration in the sense defined above bears little
importance because the script units quite perfectly match the phonemic units modern linguistic
analysis determines. A transliteration of Georgian like the one printed in Table 3, indicates the
spacial distribution of the characters on the monument; there is no need, however, to use
symbols different from the transcription characters. Regarding oriental languages, this seems
to be exceptional as we will see later on.
2. At a certain time during the Sasanian empire (224-651 A.D.), Zoroastrian priests felt the
need to fix the recitation of their sacred texts, until then handed orally, by writing, in a
manner that would preserve as many articulatory details of the pronunciation as possible. With
this aim in view, a phonetic alphabet was designed and the corpus of Zoroastrian sacred texts,
known as Avesta, was written down in this alphabet.
2.1. In Unicode Technical Report 3 (Exploratory Proposals), p.70-74, an integrative encoding
proposal is exhibited for both Pahlavi and Avestan scripts (cf. Figure 9). Indeed, the inventor of the Avestan
repertoire of phonetic symbols exploited the character stock of the so-called Pahlavi script,
i.e. the Middle Persian Book Script currently in use at his time. But the Pahlavi characters
could serve as a sort of socket symbol set only, given that most of them were multi-functional
to a great extent (e.g. there was just one character denoting the sounds n, r, w and the end
of words); for Avestan, however, each script unit was to be assigned a precise phonetic value.
This is why, in Unicode, Avestan must in any case be encoded in a separate character set, all
the more since most Avestan manuscripts offer Avestan and Pahlavi (and even Sanskrit) texts
side by side (cf. Table 7).
Table 5 shows the development of the Avestan alphabet. It makes evident that the designer of
these characters had been guided by his keen phonetic observation, quite similar to the modern
phoneticians who created the IPA notational standard.
2.2. According to the structure of the script, in analyzing the Avestan language, linguistics
starts from an unambiguous transliteration system the units of which mime the original
characters on the basis of the Latin and Greek scripts. The choice of Latin or Greek basic
characters and diacritics mirrors both the phonetic values (p 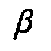 , f etc.) and the graphic
derivation (
, f etc.) and the graphic
derivation ( 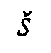 ->
->
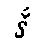 ,
, 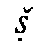 ,
,
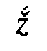 /y; k
/y; k 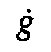 ,
,
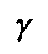 ; etc.) of the original script units
(
; etc.) of the original script units
(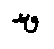 ->
->  ,
,
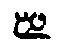 ,
, 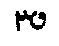 ;
;
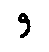 ->
-> 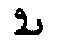 ,
,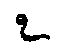 ). In
two cases (
). In
two cases (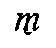 ,
, 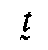 ), the form of the diacritic mark even imitates the distinctive graphic element of
the original script (
), the form of the diacritic mark even imitates the distinctive graphic element of
the original script (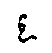 ,
, 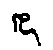 ). When Avestan transliteration is to be processed using Unicode, the
transliterative processing strategy (b) as defined above (p. 6) would be the most favourable: the
rendering engine should then be able to choose the transliteration symbols among the glyph
inventory of each code element of the Avestan character set. Method (a), on the contrary,
would provide transliteration as plain text, and we would have to add 10 precomposed
combinations to the Latin character blocks (
). When Avestan transliteration is to be processed using Unicode, the
transliterative processing strategy (b) as defined above (p. 6) would be the most favourable: the
rendering engine should then be able to choose the transliteration symbols among the glyph
inventory of each code element of the Avestan character set. Method (a), on the contrary,
would provide transliteration as plain text, and we would have to add 10 precomposed
combinations to the Latin character blocks (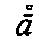 ,
,
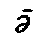 ,
, 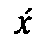 ,
,
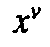 , ,
, ,
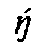 ,
, 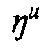 ,
, ,
) in order to establish one-to-one correspondences. But we think that a concept which shifts transliteration to the level of
rendering proves more suitable: Since transliteration symbols serve to represent the original
script, it seems quite natural to encode the original script units only.
,
, ,
) in order to establish one-to-one correspondences. But we think that a concept which shifts transliteration to the level of
rendering proves more suitable: Since transliteration symbols serve to represent the original
script, it seems quite natural to encode the original script units only.
Linguistic transcription of Avestan texts represents the phonemic interpretation achieved by
internal and external reconstruction. This should of course be handled on the level of plain
text because transcription, as stated above, behaves like any other writing system which uses
primarily Latin characters (e.g. Czech, Polish, Icelandic, etc.). Table 6 illustrates the different
layers of text handling in historical linguistics applied to the example of Avestan: (1)
digitizing of the original script document, (2) abstraction of representative graphical forms of
the original script units (i.e. creation of a computer font of the original script),
(3) transliteration, (4) transcription, (5) translation.
3. For the notation of another Old Iranian language, viz. Old Persian, a specific cuneiform
syllabary had been established at the time of Darius the Great (522486 B.C.). The creation
took place in the context of cuneiform writing still prevalent in Ancient Mesopotamia at that
time, but the syllabary essentially differs from the arrangement of the older cuneiform systems
(cf. the synopsis in Table 8). As far as the shape of the script units are concerned, Old Persian
cannot participate in a cuneiform `unification' which proposes itself when these scripts are
integrated in Unicode, the Old Persian characters consisting in individual constellations of
cuneiform elements. Additionally, the Old Persian writing system principally operates with
two sets of `consonant characters' and `vowel characters' respectively; only a few symbols
are apparently defined as to involve the vowels i or u, the other `consonant characters' being
understood as either bearing a vowel (mostly a) or no vowel at all. In some way, this reflects
the structure of the phonemic system of the language. But as far as we can guess, the writing
system was elaborated during its application, so that the existence of the characters di, mi, vi,
ku, gu, tu, du, nu, mu, ru cannot be motivated from a systematic point of view.
3.1. When an encoding for the Old Persian cuneiform script is planned, the first question
concerns the ordering of the characters. In processing, of course, the order of code elements
is irrelevant, but, on the other hand, the arrangement of any character set anticipates a certain
collation. Given that no traditional order of the Old Persian `alphabet' exists, we are free to
determine the sequence of the characters ourselves from a linguistic point of view. The
encoding proposal in UTR 3 p. 76-79 would not be the best solution. Instead, we would like
to propose an order based on the same phonetic principles as used for most syllabaries,
ancient and modern (cf. Table 8).
3.2. Transliteration of Old Persian depends on the values we attribute to the `syllabic'
characters. Consequently, there is a `consonantizing' and a
`vocalizing' transliteration strategy (cf. Table 9).
In fact both methods can be equally justified. The rendering
of the `consonant characters' of the script with an appended a-vowel throughout reflects the
fact that they were modelled on the basis of typical cuneiform characters, representing
sequences of consonant plus vowel (CV). The consonantizing method, on the other hand,
presumes that in the Old Persian writing system the characters are conceived as generic
symbols that mark syllabic classes defined by the consonants involved (k for ka, ki, ku etc.).
If we were to decide on the notation according to a given context, we would no longer
produce transliterations but transcriptions, switching to and fro between `vocalizing' and
`consonantizing' renderings of symbols like 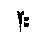 read once as k, once as ka.
read once as k, once as ka.
Transliterative processing of Old Persian using Unicode could be a glyph representation
process as considered above for Avestan, provided the rendering engine enables us to
implement a one-to-n mapping of original script and glyph units and to choose between the
`vocalizing' and `consonantizing' methods. Otherwise we should have to encode the
transliterated text just like the transcribed text, using the characters of the Unicode Latin
Character Blocks (cf. Figure 10).
4. Encoding transcriptional and transliterational materials (according to method (a), p. 6),
historical linguists will always be tempted to make use of the precomposed characters already
existing in Unicode. This would be an economical approach. A first evaluation made in the
course of the development of transcription fonts for Indo-Europeanists (cf. http://coli.uni-sb.de/~cmb) with the view of administering the TITUS text database
(cf. http://titus.uni-frankfurt.de/texte/texte.htm), showed that on the basis of existing Unicode characters, transcription
and/or transliteration of texts from very many ancient Indo-European languages can be
achieved in accordance with the principles established and adopted by historical linguists. An
ever increasing set of additional characters (such as the one printed in Table 10) will be
required though whenever we aim at representing (or rather mirroring) all aspects of human
textual tradition.
4.1. A rather hybrid method would consist in using the existing precomposed combinations
and to encode the missing combinations analytically (cf. Figure 11). This would establish enormous difficulties concerning sorting and other processes where overlay modules are required that define
the value of character sequences containing superscripts and the like in the specific collation.
Although this is a possible strategy, it would result in a huge amount of manpower to be
invested before Unicode can be used for these transliteration and transcription systems. An
even worse encoding strategy would consist in dispensing with precomposed Unicode characters altogether. In addition to the collation complexity referred to above, this would entail an
even higher dependence on software development than the hybrid strategy discussed before.
4.2. As far as transliteration is concerned, less problems would occur if we could widely
adopt method (b) consisting in a glyph mapping onto the original script units. But as we have
stated above, it is necessary in this case that the original script is fully encoded with all its
units. This can easily be demonstrated by one other example. If we want to represent the
divergent witnesses of the Middle High German Nibelungenlied, we have to face not only
special characters such as 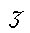 but also a nearly indefinite number of seemingly ad-hoc
combinations of plain and superscript characters such as
but also a nearly indefinite number of seemingly ad-hoc
combinations of plain and superscript characters such as 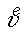 ,
,
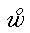 (cp. the sample passage shown
in Table 11). If we compare the structuring of the Unicode Latin Character Blocks, these
combinations could easily be treated as separate units of the original script just as the
additional characters of the Czech alphabet (, and the like) are treated in Unicode; for an
adequate rendering, this would be the best solution. The same holds true then for their
transliteration, for in the case of the Nibelungenlied manuscripts the original script and the
transliteration is virtually the same because the Medieval Latin script is nothing but a style
variant of the plain Latin alphabet just as the transliterational script is. Of course it would be
possible to use Composed Character Sequences in such cases too; but this would require at
least an additional set of superscript characters to be treated as diacritics.
(cp. the sample passage shown
in Table 11). If we compare the structuring of the Unicode Latin Character Blocks, these
combinations could easily be treated as separate units of the original script just as the
additional characters of the Czech alphabet (, and the like) are treated in Unicode; for an
adequate rendering, this would be the best solution. The same holds true then for their
transliteration, for in the case of the Nibelungenlied manuscripts the original script and the
transliteration is virtually the same because the Medieval Latin script is nothing but a style
variant of the plain Latin alphabet just as the transliterational script is. Of course it would be
possible to use Composed Character Sequences in such cases too; but this would require at
least an additional set of superscript characters to be treated as diacritics.
5. We should be glad if our contribution might have helped to show that whenever ancient
languages and historic scripts are concerned, a lot of reasoning is necessary before they can
be adopted by Unicode in a way sufficient for both a reliable representation of original
documents and linguistic analysis. It goes without saying that specialists from throughout the
world should work together with respect to this aim.
Copyright for this text: C.M. Bunz / Jost Gippert, Frankfurt a/M, 9.3.1997.
No parts of this document may be republished in any form without prior permission by the copyright holders.