

Als ich Anfang der achtziger Jahre zum ersten Mal einen der damals geradezuaus dem Boden schießenden Computerläden betrat, hatte ich nur eine eher vage Vorstellung davon, was ich dort wollte. Das, was mir der Verkäufer vorzuschlagen hatte, war es jedenfalls nicht: "Ah, Sie sind Geisteswissenschaftler? Dann suchen Sie so etwas wie eine bequemere Schreibmaschine?" - "Nein," entgegnete ich, "darum geht es mir nicht, ich komme mit meiner elektrischen ganz gut zurecht. Mir geht es vielmehr darum, ein Hilfsmittel zu finden, das mich bei meiner sprachwissenschaftlichen Forschungstätigkeit selbst unterstützt." - "Können Sie mir vielleicht etwas genauer erklären, was Sie meinen?" - "Nun, nehmen wir ein einfaches Beispiel. Stellen wir uns vor, jemand behauptet, daß Goethe in seinen Schriften als Vergangenheitsform des Wortes fragen nicht das heute übliche er fragte, sondern regelmäßig die Form er frug benutzt habe. Ich nehme an, es müßte mit einem Computer doch leicht möglich sein, so eine Behauptung zu überprüfen, vorausgesetzt, die Schriften Goethes lägen in einer für den Computer 'lesbaren' Form vor." - "Ja," meinte der Verkäufer, das sei wohl möglich, aber dann müßte man Goethes Werke zuerst vollständig eingeben. Außerdem beanspruchten diese doch sicher eine Menge Speicherplatz, und das dafür geeignete neue Medium "Festplatte" sei enorm teuer. Ich beschloß also, die Anschaffung noch eine gewisse Zeit hinauszuschieben, bis ein derartiges Unterfangen nicht mehr utopisch und unbezahlbar wäre.
Seit dem "verpaßten Einstieg" sind nun bald 15 Jahre vergangen, in denen sich nicht nur die Preise verändert haben. In einem Punkt mag der Verkäufer zwar bis heute recht gehabt haben: Noch immer steht bei Sprachwissenschaftlern, die einen Computer benutzen, die Funktion der "komfortableren Schreibmaschine" im Vordergrund, und auch für mich ist er in dieser Hinsicht unverzichtbar geworden. Wenn die "flüchtige" Texterfassung - das Schreiben von Briefen, Aufsätzen, Büchern - aber gerade in jüngerer Zeit ihre Priorität zu verlieren beginnt, so dürften dafür nicht zuletzt die Möglichkeiten verantwortlich sein, die die internationale Vernetzung im Hinblick auf eine zweckmäßige Unterstützung der Forschungstätigkeit mit sich bringt. Im folgenden sei kurz geschildert, in welcher Form auch meine Mitarbeiter und ich hierzu beizutragen versuchen.
Wie also sprach Zarathustra?
Mit dem "Goetheschen" Beispiel habe ich bereits einen ganz wesentlichen Bereich der Aktivitäten umrissen, auf die sich unsere Bemühungen in den letzten Jahren konzentriert haben. Die Vergleichende Sprachwissenschaft birgt, zumindest soweit sie sich auf die historischgenealogische Dimension des Sprachvergleichs bezieht, immer auch eine philologische Komponente, insofern ihre Untersuchungsmaterialien in schriftlichen Zeugnissen unterschiedlichster Epochen niedergelegt sind. Im Falle der indogermanischen Sprachfamilie, deren Erforschung innerhalb der Geschichte der Sprachwissenschaft auf die längste Tradition zurückblicken kann, ist die Menge der hierfür in Frage kommenden Texte besonders groß: Sie erstreckt sich von den Keilschrifttafeln der Hethiter im Alten Anatolien bis hin zu beliebigen Textprodukten heute gesprochener "Weltsprachen" wie des Englischen, des Französischen oder auch des Deutschen. Natürlich sind nicht alle diese Textzeugnisse für den Sprachvergleich, d.h. für die Beantwortung der Frage, wie die einzelnen Sprachen bzw.Sprachstufen miteinander in historischer Verbindung stehen, von gleicher Relevanz. Die größte Bedeutung wird zumeist den jeweils ältesten Vertretern der einzelnen "Zweige" beigemessen, also etwa den Hymnen des Rigveda innerhalb des Altindischen (Sanskrit), den auf den Religionsgründer Zarathustra zurückgehenden "avestischen" Gathas innerhalb des Altiranischen, den Epen Homers innerhalb des Altgriechischen oder den "altlateinischen" Stücken des Plautus innerhalb des "italischen" Zweiges. Auf alle diese Texte lassen sich aber ganz ähnliche Fragestellungen anwenden, wie sie oben an Goethes Werken illustriert wurden, und die Applikation derartiger Fragestellungen ist das "tägliche Brot" eines indogermanistischen Forschers. Es lag also nahe, die Speicherungs- und Analysefähigkeiten des Computers auch auf derartige Texte anzuwenden, sobald nur die nötigen Kapazitäten hierfür gegeben waren.
Ein Thesaurus entsteht
Diese Idee wurde nun nicht etwa einmal und an einem Ort "geboren", sondern hatte sich zumindest in den USA bereits lange, bevor ich meinen ersten Einstieg wagte, unter Sprachwissenschaftlern und Philologen verbreitet. Allerdings bestand gegenüber heute noch ein signifikanter Unterschied: In den siebziger Jahren hatte noch niemand daran gedacht, Textmengen wie die insgesamt 1.028 Lieder umfassende Sammlung der Rigveda-Samhita oder gar die gesamte überlieferte Textmenge des klassischen griechischen Altertums auf Festplatten oder CDs zu speichern und mit einem Personal Computer zu verarbeiten; gearbeitet wurde vielmehr an Großrechneranlagen, und das Speichermedium waren Magnetbänder. Dennoch bilden einige der damals eingegebenen Texte den Grundstock eines umfangreich angelegten Thesaurus, der als Textdatenbank in absehbarer Zeit die gesamte Masse der für den indogermanistischen Sprachvergleich relevanten schriftlichen Überlieferung erfassen soll und dessen Organisation ich seit 1987 in Angriff genommen habe [1].
Textdatenbank und Internet: Perspektiven weltweiter Kooperation
In welchem Verhältnis steht diese Textdatenbank nun zum Internet? Zunächst einmal in einem "nehmenden" Verhältnis, indem ihr weiterer Ausbau von den Möglichkeiten des weltweiten Netzes profitiert. Dabei ist zu berücksichtigen, daß die Textdatenbank so, wie sie von Anfang an konzipiert wurde, von der Beteiligung möglichst vieler Wissenschaftler abhängt: jeder, der einzelne Texte oder Corpora beiträgt, hat Zugang zu der gesamten angesammelten Textmasse. Dieses Konzept wurde seit der Grundlegung des Projekts beibehalten, weil es zum einen den Arbeitsaufwand in vernünftiger Weise streut (derzeit sind rund 50 Kolleginnen und Kollegen aus Deutschland, Europa und Übersee beteiligt), und zum anderen, weil es eine rasche Weiterentwicklung gewährleistet. Seitdem nun von unterschiedlichsten Forschungsinstitutionen die durch das World Wide Web (WWW) eröffnete Möglichkeit genutzt wird, ohne großen publikatorischen Aufwand eigene "Errungenschaften" bekanntzumachen, haben sich zweierlei überraschende Erkenntnisse ergeben: Zum einen, daß die elektronische Verarbeitung "exotischer" Textmaterialien bereits ein weit größeres Ausmaß angenommen hat, als allgemein bekannt schien, und zum anderen, daß trotz mehrfacher Bekanntgabe an einschlägigen Orten (in Fachzeitschriften oder auf internationalen Kongressen) das Projekt einer indogermanistischen Textdatenbank den Sprachwissenschaftlern nicht einmal im deutschen Sprachraum allgemein geläufig war. Daß über existierende Vorhaben nunmehr ständige wechselseitige Information möglich ist, die bereits in zahlreichen Fällen zu einer Kooperation geführt hat (etwa mit M. Tokunaga von der Universität Kyoto in Japan, von dem die elektronischen Texte der beiden großen Sanskritepen, des Mahâbhârata - vergleiche Abbildungen 1a und 1b - und des Râmâyana zur Verfügung gestellt wurden), ist somit unmittelbar dem internationalen Netz zu verdanken.

Abbildung 1a: Mausklick zum Vergrößern

Abbildung 1b: Mausklick zum Vergrößern
Datenaustausch via Filetransfer
Selbstverständlich darf nicht übersehen werden, daß auch der Austausch der Daten selbst, unabhängig von ihrem Umfang, durch das Internet wesentlich leichter und schneller bewerkstelligt werden kann als etwa durch die Versendung über Disketten oder andere Speichermedien. Um nur ein Beispiel zu nennen: An der University of Toronto in Kanada war in den frühen achtziger Jahren das gesamte Textcorpus des Altenglischen eingespeichert worden, um eine sogenannte Textstellenkonkordanz, d.h. einen Index der in den Texten erscheinenden Wortformen mit ihren Belegstellen, zu erzeugen; diese Konkordanz liegt seit längerem in Microficheform publiziert vor [2]. Bereits 1988 erhielt ich von den Torontoer Kollegen die Zusage, daß sie das elektronische Corpus für die Textdatenbank zur Verfügung stellen würden. Angesichts der enormen Datenmenge - es handelt sich um rund 170 einzelne Textfiles mit insgesamt circa 25 MB, d.h. 25 Millionen Zeichen (Buchstaben, Satzzeichen u.ä.) - erschien die Frage des Transfers bis vor kurzem jedoch kaum lösbar, wollte man nicht auf für PCs schwer benutzbare Magnetbänder zurückgreifen. Anfang dieses Jahres gelang es dann, die gesamte Datenmenge durch einen rund dreistündigen "file transfer" von einem Server des Oxford Text Archive aus England nach Frankfurt zu übertragen. Heute liegt das gesamte altenglische Corpus innerhalb unserer Datenbank in einer vorindizierten Form bereit, die es ermöglicht, in weniger als einer Sekunde sämtliche Belege auch häufig verwendeter Wortformen samt ihrem Kontext auf den Bildschirm zu holen. Die Vorindizierung erfolgte dabei mit dem Programm Wordcruncher, das in den achtziger Jahren von der Brigham Young University in Utah entwickelt wurde. Durch den Versuch, die einzelnen Teilcorpora in einer übereinstimmenden Filestruktur aufzubereiten, unterscheidet sich unsere Textdatenbank übrigens ganz wesentlich von anderen, der einfachen Anhäufung gewidmeten Textarchiven wie demjenigen in Oxford.
Eine alte Crux: Codierung von Schriften und Zeichen
In Zukunft soll das Verhältnis der Textdatenbank zum Internet
natürlich nicht nur ein nehmendes bleiben. Bevor aber die große
Textmasse gewissermaßen frei verfügbar an die
sprachwissenschaftlich interessierte Fachwelt weitergegeben werden kann,
sind noch verschiedene Probleme zu lösen. Das betrifft zum einen die
Frage der Codierung. Fast jede der Sprachen, deren relevantes Textmaterial
in die Sammlung integriert wurde oder werden soll, ist mit einer eigenen
schriftlichen Tradition versehen, und fast alle diese Traditionen weisen
besondere Eigenheiten auf, die den Computeranwender vor Probleme stellen. Im
einfachsten Fall geht es nur um die Verwendung "skurriler"
Zusatzzeichen zum Lateinalphabet wie im Falle des Litauischen, das
Kombinationen wie
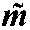 oder
oder
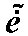 benutzt.
In den meisten Fällen aber
geht es um spezielle, mit der Lateinschrift völlig unvereinbare
Schriftsysteme wie die altindische "Devanagari"-Silbenschrift
(Abb. 1 und Abb. 2)
mit ihren zahlreichen Ligaturen oder die linksläufige "Avestaschrift"
(Abbildung 3). Obwohl sich die Sprachwissenschaft in
solchen Fällen immer mit Transkriptionssystemen hat helfen können,
und obwohl über die letzten zehn Jahre hinweg für verschiedene
Rechnersysteme befriedigende Lösungen entwickelt wurden, um sogar die
Originalschriften verwaltbar und auf Bildschirm und Drucker sichtbar zu
machen, fehlt doch nach wie vor ein allgemein akzeptiertes und vor allem
systemunabhängiges Codierungsverfahren, das eine - für die
sprachwissenschaftliche Analyse unabdingbare - umkehrbar-eindeutige
Repräsentation der Originalzeichen ermöglichen würde [3]. Alle derzeit existierenden Lösungsversuche
haben nur eines gemeinsam: Sie laufen Gefahr, beim nächsten
"Siegeszug" eines neuen Betriebssystems schlagartig unbrauchbar zu
werden.
benutzt.
In den meisten Fällen aber
geht es um spezielle, mit der Lateinschrift völlig unvereinbare
Schriftsysteme wie die altindische "Devanagari"-Silbenschrift
(Abb. 1 und Abb. 2)
mit ihren zahlreichen Ligaturen oder die linksläufige "Avestaschrift"
(Abbildung 3). Obwohl sich die Sprachwissenschaft in
solchen Fällen immer mit Transkriptionssystemen hat helfen können,
und obwohl über die letzten zehn Jahre hinweg für verschiedene
Rechnersysteme befriedigende Lösungen entwickelt wurden, um sogar die
Originalschriften verwaltbar und auf Bildschirm und Drucker sichtbar zu
machen, fehlt doch nach wie vor ein allgemein akzeptiertes und vor allem
systemunabhängiges Codierungsverfahren, das eine - für die
sprachwissenschaftliche Analyse unabdingbare - umkehrbar-eindeutige
Repräsentation der Originalzeichen ermöglichen würde [3]. Alle derzeit existierenden Lösungsversuche
haben nur eines gemeinsam: Sie laufen Gefahr, beim nächsten
"Siegeszug" eines neuen Betriebssystems schlagartig unbrauchbar zu
werden.

Abbildung 3: Mausklick zum Vergrößern
Eine ungeklärte Frage: Keilschrifttafel und Copyright
Ein weiteres Problem stellt eine bis heute nicht eindeutig geklärte rechtliche Frage dar, nämlich inwieweit eine Verfügbarmachung von Textmaterialien über das internationale Netz eine Verletzung von Urheberrechten bedeuten kann. Seitens der "interessierten Kreise", die eine solche Gefahr sehen, ist dabei weniger an die Urheberrechte antiker Autoren wie des Hethiterkönigs Anitta (als Autor des sogenannten "Anitta-Texts", eines in althethitischer Sprache überlieferten historischen Berichts aus dem 18. Jahrhundert vor Christus; Abb. 4) oder des altindischen Sängers Vasistha (als des Dichters zahlreicher rigvedischer Hymnen) gedacht, sondern an die Rechte zeitgenössischer Bearbeiter, Herausgeber oder Verleger derartiger Texte. Es wird hoffentlich nicht mehr allzu lange dauern, bis sich die Erkenntnis durchsetzt, daß eine elektronische Auswertung edierter und publizierter Textmaterialien zur Gewinnung neuer sprachwissenschaftlicher Erkenntnisse nicht geistiger Diebstahl ist, sondern lediglich die Fortführung langjähriger wissenschaftlicher Praxis mit anderen Mitteln. Der Unterschied zwischen einem Zettelkasten und einer Datenbank besteht in dieser Hinsicht im wesentlichen nur in der Effektivität.

Abbildung 4: Mausklick zum Vergrößern
Elektronische Texte: Texte mit Eigenleben
Dennoch gibt es noch einen zweiten, nicht zu unterschätzenden Unterschied zwischen der Verarbeitung originalsprachlicher Textdaten mit dem Computer und der klassischen Herausgabetätigkeit: Während eine gedruckte Edition immer auf dem wissenschaftlichen Stand bleibt, den sie bei der Drucklegung darstellte, "leben" elektronisch gespeicherte und bearbeitete Texte ständig weiter; d.h., sie können ständig durch die Berücksichtigung neuer Erkenntnisse und Untersuchungsmethoden an den Forschungsstand angepaßt werden. Dies hat freilich auch Nachteile, insofern sich von den elektronisch aufbereiteten Texten schnell unterschiedliche "Varianten" entwickeln, je nachdem, wer sie mit welchen Absichten benutzt und an die eigenen Bedürfnisse anpaßt. Welcher Art diese "Verästelungen" sind, mögen die in Abbildung 2 dargestellten Ausprägungen einer Rigveda-Strophe zeigen, die den mir zugänglichen Bearbeitungen entnommen sind. Zukünftig wird es eine der wichtigsten Funktionen der Datenbank sein, derartige elektronische Varianten wieder zusammenzuführen, die in ihnen enthaltenen Erkenntnisse miteinander zu vereinigen und im Hinblick auf weiteren Erkenntnisgewinn auszuwerten. Es versteht sich von selbst, daß auch die Sammlung von aus den Texten hervorgehenden Sekundärinformationen - Wörterverzeichnisse, Glossare, grammatische Sammlungen - in steigendem Maße einen Bestandteil des Projekts ausmachen wird.
TITUS: Ein umfassendes sprachwissenschaftliches Informationssystem
Über die Archivierung objektbezogener Daten hinaus soll das Projekt, das seit der Dritten Fachtagung zum "Computereinsatz in der Historisch-Vergleichenden Sprachwissenschaft" in Dresden (Oktober 1994) unter dem prägnanten Namen "TITUS" geführt wird ("Thesaurus Indogermanischer Text- und Sprachmaterialien"), mehr und mehr auch auf andere Bereiche der sprachwissenschaftlichen Forschung ausgedehnt werden. Die zentrale Rolle wird dabei ein umfassendes bibliographisches Informationssystem bilden, das mit dem Anspruch größtmöglicher Aktualität Neuerscheinungen aus allen das Fach betreffenden oder tangierenden Gebieten erfassen soll. Auch hierbei wird das Internet eine entscheidende Funktion ausüben: Die erwünschte Aktualität ist gerade dadurch zu erzielen, daß auf eine Drucklegung verzichtet wird und die Informationen lediglich "online" verarbeitet werden; und die Zusammenführung der einzelnen Informationen, zu der ein einzelnes Institut kaum je in der Lage wäre, soll möglichst bald auf zahlreiche Partner verteilt werden, deren gemeinsame Verbindung eben im Internet besteht. Hierzu gibt es bereits feste Absprachen mit Kollegen an den Universitäten Prag, Wien, Kopenhagen, Leiden, Maynooth u.a. (derzeit wird die Bibliographie in einem "Probelauf" noch allein von Frankfurt aus bearbeitet). Unter denselben Prämissen - Beteiligung möglichst vieler Partner zwecks der Zusammenführung sich ergänzender Informationen - zeichnen sich noch einige weitere Einsatzbereiche des TITUS-Projekts ab, die es letztlich zu einem umfassenden fachbezogenen Informationssystem heranreifen lassen sollen. So können bereits jetzt regelmäßig aktuelle Mitteilungen über fachliche Veranstaltungen (Kongresse, Konferenzen, aber auch universitäre Lehrprogramme), freie Stellen und Ausschreibungen, Projekte und Forschungsvorhaben etc. abgerufen werden. Alle derartigen Informationen zusammenzutragen, erfordert dank der internationalen Vernetzung nur einen äußerst geringen (Speicher- und Zeit-)Aufwand vor Ort. Um z.B. auf eine Konferenz hinzuweisen, die an einer amerikanischen Universität stattfinden soll, braucht lediglich die "Adresse" des von den Veranstaltern verfaßten Einladungstextes in die dafür vorgesehene "WWW-Seite" eingetragen zu werden - vorausgesetzt natürlich, die Veranstalter bieten ihren Einladungstext selbst im Internet an.
Rückblick
Die eingangs aufgeworfene Frage hinsichtlich der Grammatik Goethes ist heute, ganz wie ich es seinerzeit vermutet hatte, in Sekundenschnelle zu beantworten: In seinen Werken, die in elektronischer Form seit einigen Jahren verfügbar sind [4], kommt die oft für "korrekter" gehaltene Form er frug lediglich ein einziges Mal vor, nämlich in den "Venetianischen Epigrammen" von 1790 (Abb. 6); normalerweise, nämlich insgesamt 222mal, hat Goethe er/sie fragte gebraucht. Es ist anzunehmen, daß Goethe selbst dem Irrtum unterlegen war, er frug sei die "ältere" und damit für den antikisierenden Hexameter angemessenere Form.

Abbildung 6: Mausklick zum Vergrößern